EP180: Python vs Java
이번 주 시스템 설계 리프레셔:
- Python vs Java
- Design Patterns Cheat Sheet
- CI/CD Simplified Visual Guide
- How Apache Kafka Works?
- Load Balancers vs API Gateways vs Reverse Proxy
Python vs Java
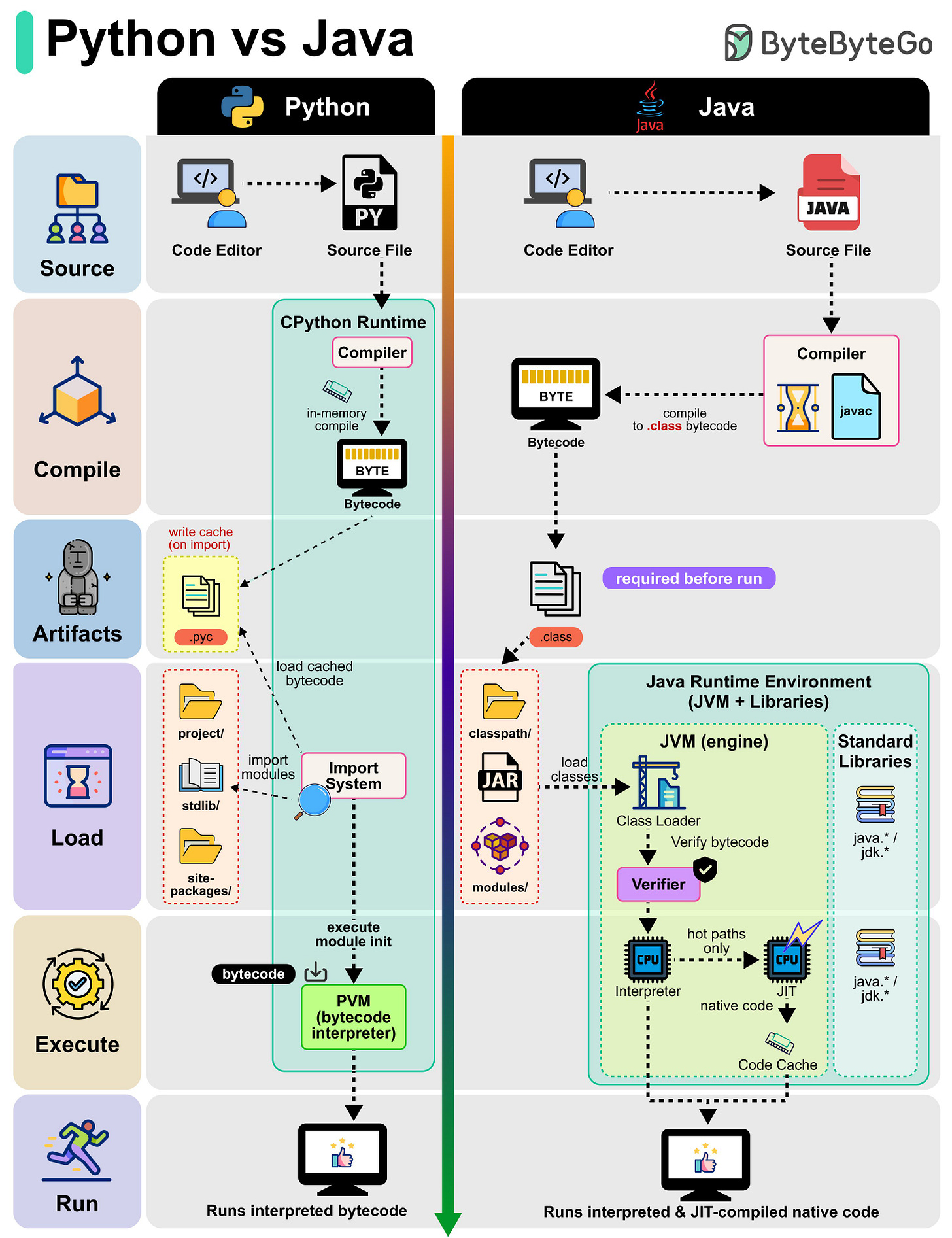
Python 스크립트나 Java 프로그램을 실행할 때 내부에서 무슨 일이 일어나는지 궁금하셨나요? 함께 알아보겠습니다:
Python (CPython Runtime):
- Python 소스 코드(.py)는 메모리에서 자동으로 bytecode로 컴파일됩니다.
- Bytecode는 .pyc 파일에 캐시될 수도 있어서, 캐시된 버전을 사용하면 재실행 속도가 빨라집니다.
- Import System이 모듈과 dependency들을 로드합니다.
- Python Virtual Machine(PVM)이 bytecode를 한 줄씩 해석하므로, Python은 유연하지만 상대적으로 느립니다.
Java (JVM Runtime):
- Java 소스 코드(.java)는 javac를 사용해 .class bytecode로 컴파일됩니다.
- Class Loader가 bytecode를 Java Runtime Environment(JVM)에 로드합니다.
- Bytecode가 검증되고 실행됩니다.
- JVM은 Interpreter와 JIT Compiler를 모두 사용하며, 자주 사용되는 코드(hot paths)는 native machine code로 변환되어 Java를 더 빠르게 만듭니다.
여러분은 어떠신가요? Python의 유연성과 Java의 일관된 성능 중 어느 쪽을 선호하시나요?
Design Patterns Cheat Sheet
이 치트시트는 각 패턴과 사용 방법을 간략하게 설명합니다.
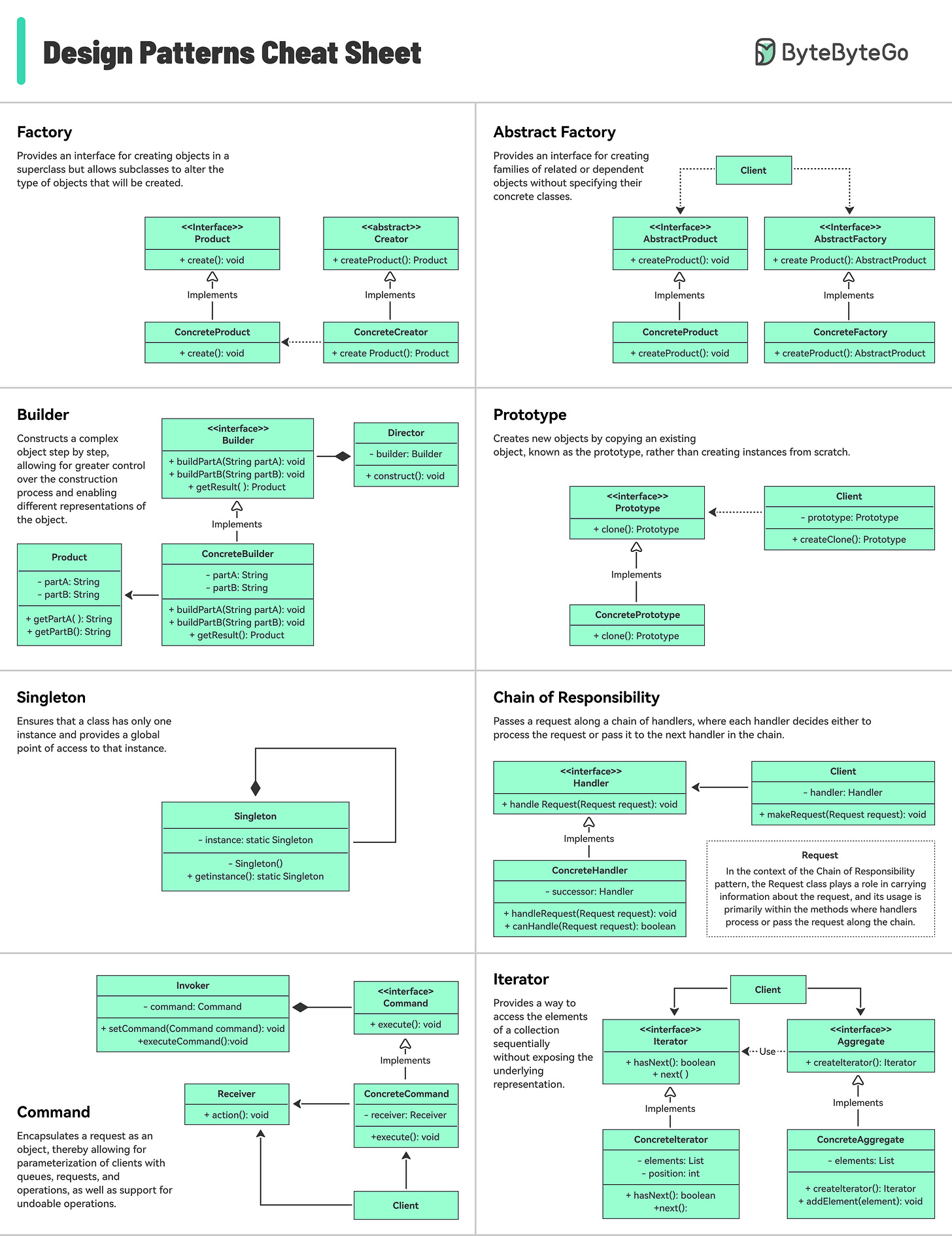
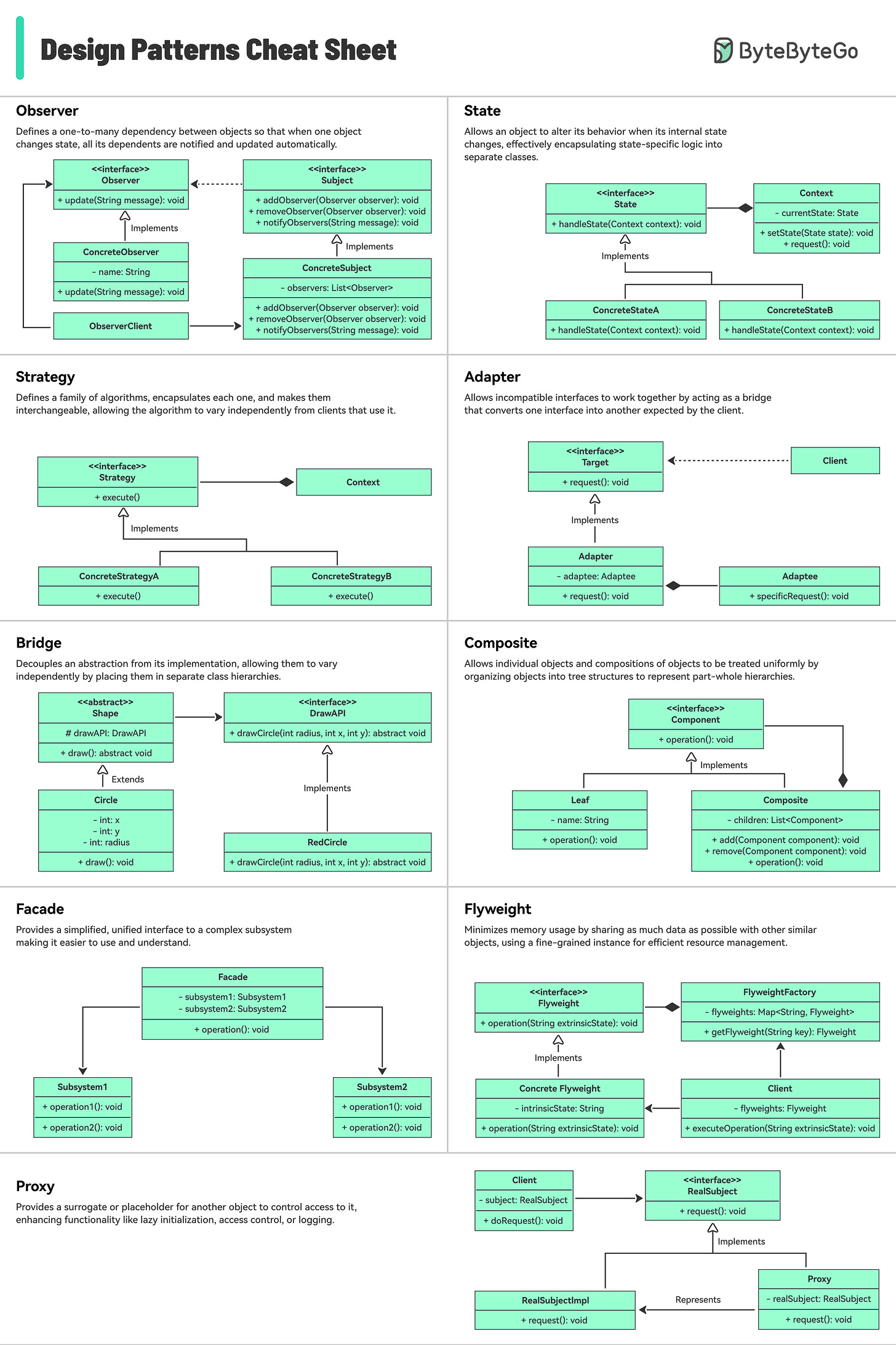
포함된 내용:
- Factory
- Builder
- Prototype
- Singleton
- Chain of Responsibility
- 그 외 다수!
CI/CD Simplified Visual Guide
개발자든, DevOps 전문가든, 테스터든, 현대 IT 업무에 종사하는 누구든 CI/CD pipeline은 소프트웨어 개발 프로세스의 필수적인 부분이 되었습니다.
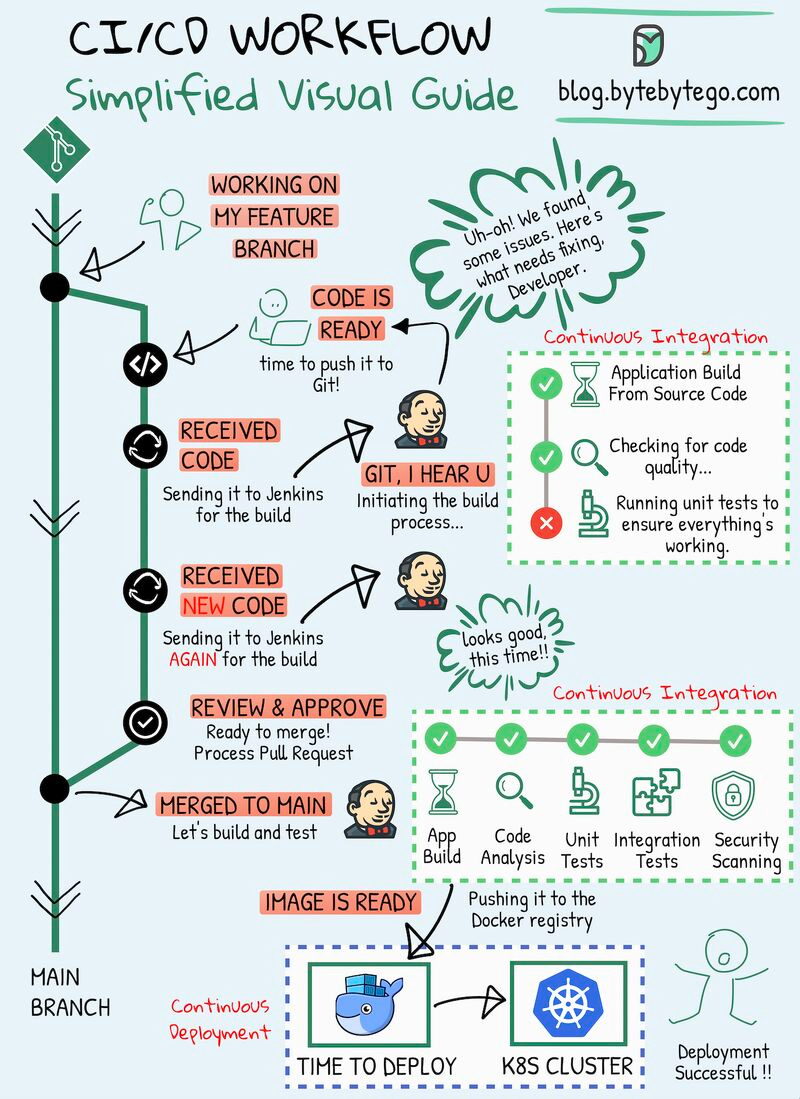
**Continuous Integration(CI)**은 코드 변경사항을 공유 repository에 자주 통합하는 practice입니다. 이 프로세스에는 새 코드가 기존 코드와 잘 작동하는지 확인하는 자동 검사가 포함됩니다.
**Continuous Deployment(CD)**는 이러한 코드 변경사항을 자동으로 실제 환경에 배포하는 것을 담당합니다. 새 코드를 production으로 이동하는 프로세스가 원활하고 안정적으로 이루어지도록 보장합니다.
이 비주얼 가이드는 소프트웨어를 더 효과적으로 만들고 배포하는 방법을 이해하고 개선하는 데 도움이 되도록 설계되었습니다.
여러분은 어떠신가요? 프로젝트에서 CI/CD를 구현할 때 가장 효과적인 도구나 전략은 무엇인가요?
How Apache Kafka Works?
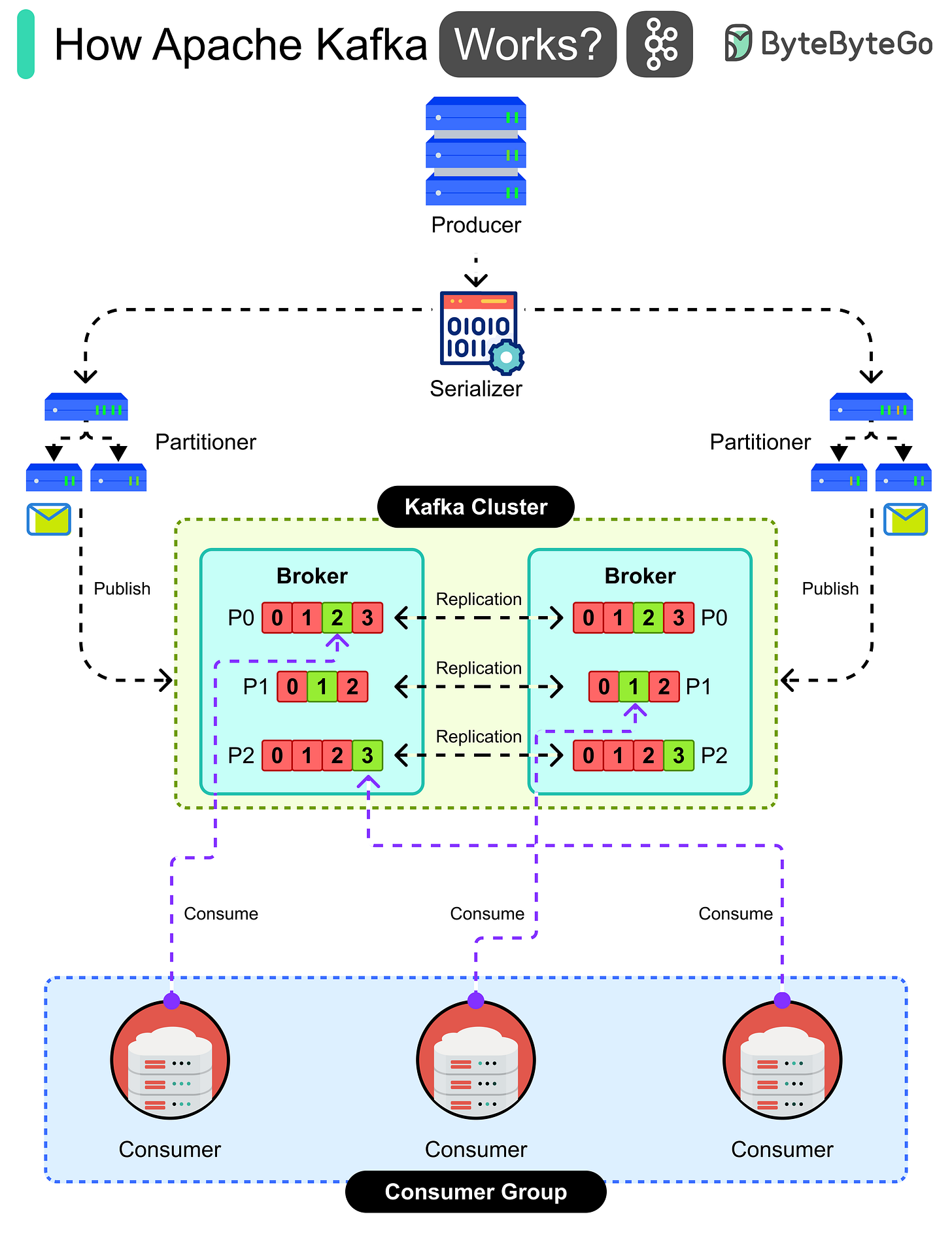
Apache Kafka는 producer가 데이터를 publish하고 consumer가 실시간으로 구독할 수 있게 해주는 분산 이벤트 스트리밍 플랫폼입니다. 작동 방식을 살펴보겠습니다:
- Producer application이 웹사이트 클릭이나 결제 이벤트 같은 데이터를 생성합니다.
- 데이터는 serializer에 의해 Kafka가 처리할 수 있도록 bytes로 변환됩니다.
- Partitioner가 메시지가 어느 topic partition으로 가야 할지 결정합니다.
- 메시지는 여러 broker로 구성된 Kafka cluster에 publish됩니다.
- 각 broker는 topic의 partition을 저장하고 안전을 위해 다른 broker에 복제합니다.
- Partition 내의 메시지는 순서대로 저장되며 읽기가 가능합니다.
- Consumer group이 topic을 구독하고 데이터 처리를 담당합니다.
- Group 내의 각 consumer는 작업 부하를 분산하기 위해 서로 다른 partition에서 읽습니다.
- Consumer는 대시보드 업데이트나 액션 트리거와 같은 작업을 실시간으로 데이터를 처리합니다.
여러분은 어떠신가요? Apache Kafka를 사용해 보셨나요?
Load Balancers vs API Gateways vs Reverse Proxy! 그리고 이들은 어떻게 함께 작동할까요?
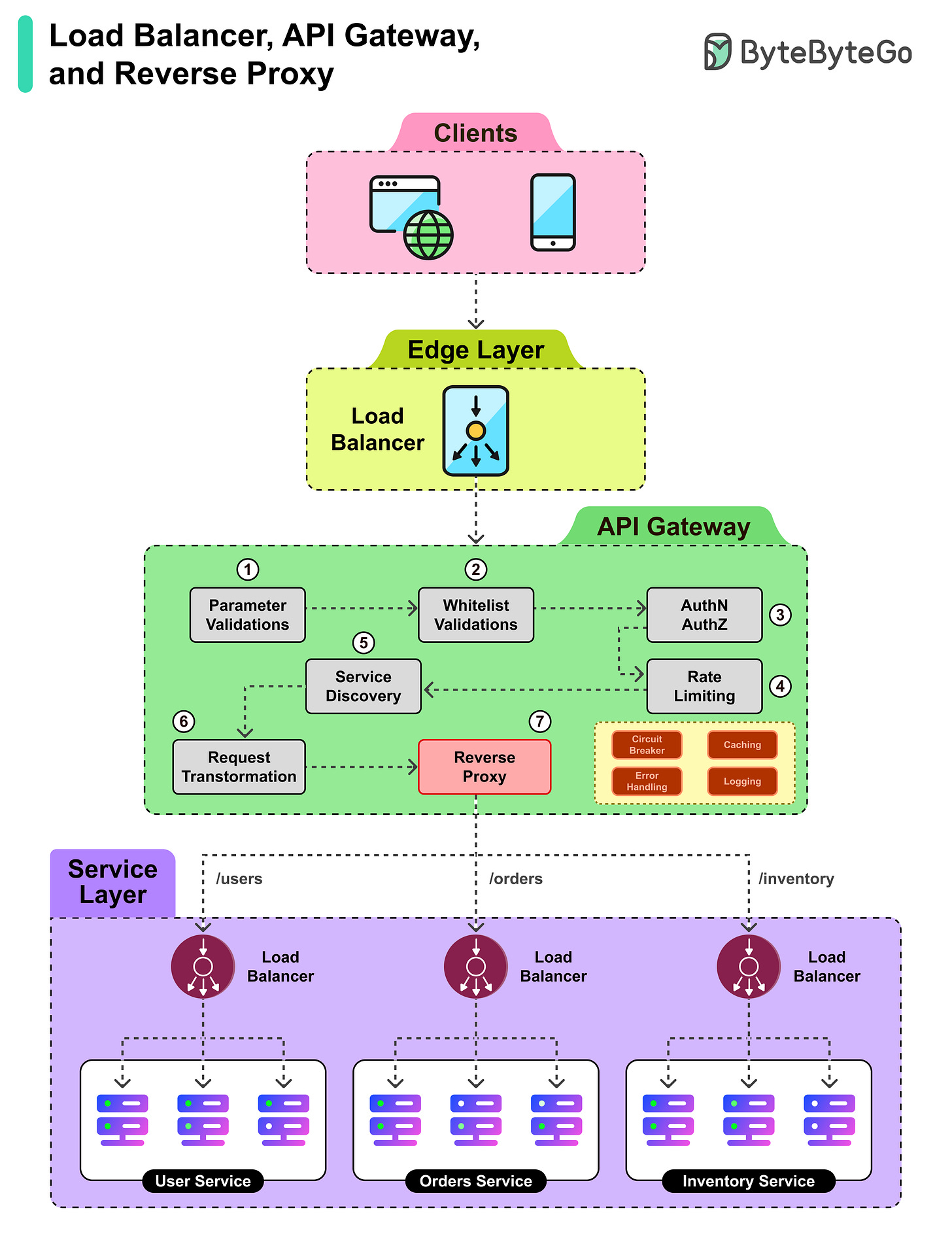
Load balancer, API gateway, reverse proxy는 서로의 기능이 겹치는 경우가 많지만, 프로젝트에서 활용할 수 있는 고유한 역할도 있습니다.
- 클라이언트 요청은 먼저 edge load balancer에 도달하며, 단일 진입점을 제공하고 트래픽을 API Gateway로 분산합니다.
- API Gateway가 인수하여 요청이 올바른 형식인지 확인하기 위해 초기 파라미터 검증을 수행합니다.
- 다음으로 whitelist 검증이 소스가 신뢰할 수 있고 API에 접근이 허용되는지 확인합니다.
- Authentication과 authorization이 요청자의 신원과 권한을 검증합니다.
- Rate limiting이 클라이언트가 너무 많은 요청으로 시스템을 과부하시키지 않도록 보장합니다.
- 마지막으로, gateway 내부의 reverse proxy가 요청을 올바른 service endpoint로 전달합니다.
- Service layer에서 또 다른 load balancer가 대상 microservice의 여러 instance에 요청을 분산합니다.
- 선택된 service instance가 요청을 처리하고 클라이언트에게 응답을 반환합니다.
여러분은 어떠신가요? 애플리케이션에서 load balancer, API gateway, reverse proxy를 사용해 보셨나요?
Thank you for reading.