EP193: 2025년에 알아야 할 데이터베이스 유형
2025년에 알아야 할 데이터베이스 유형
이제 모든 상황에 맞는 단일 데이터베이스는 존재하지 않습니다. 현대 애플리케이션은 실시간 분석부터 AI를 위한 벡터 검색까지 다양한 데이터베이스 유형에 의존합니다. 어떤 유형을 사용해야 하는지 아는 것이 시스템 성능을 좌우할 수 있습니다.

-
Relational: 전통적인 행-열 구조의 데이터베이스로, 구조화된 데이터와 트랜잭션에 적합합니다.
-
Columnar: 분석에 최적화되어 있으며, 빠른 집계를 위해 데이터를 열 단위로 저장합니다.
-
Key-Value: 데이터를 간단한 키-값 쌍으로 저장하여 빠른 조회가 가능합니다.
-
In-memory: 초저지연 조회를 위해 데이터를 RAM에 저장하며, 캐싱이나 세션 관리에 이상적입니다.
-
Wide-Column: 분산 노드에 걸쳐 대용량의 반구조화 데이터를 처리합니다.
-
Time-series: 시간을 주요 차원으로 하는 메트릭, 로그, 센서 데이터에 특화되어 있습니다.
-
Immutable Ledger: 변조 방지 및 암호학적으로 검증 가능한 트랜잭션 로그를 보장합니다.
-
Graph: 복잡한 관계를 모델링하며, 소셜 네트워크와 사기 탐지에 적합합니다.
-
Document: 유연한 JSON 형태의 저장 방식으로, 스키마가 변화하는 현대 앱에 적합합니다.
-
Geospatial: 지도, 경로, 공간 쿼리와 같은 위치 기반 데이터를 관리합니다.
-
Text-search: 전문 인덱싱과 검색, 랭킹, 필터, 분석 기능을 제공합니다.
-
Blob: 이미지, 비디오, 파일과 같은 비구조화 객체를 저장합니다.
-
Vector: 임베딩 간 유사도 검색을 통해 AI/ML 앱을 지원합니다.
Apache Kafka vs. RabbitMQ
Kafka와 RabbitMQ는 둘 다 메시지를 처리하지만, 근본적으로 다른 문제를 해결합니다. 분산 시스템을 설계할 때 이 차이를 이해하는 것이 중요합니다.
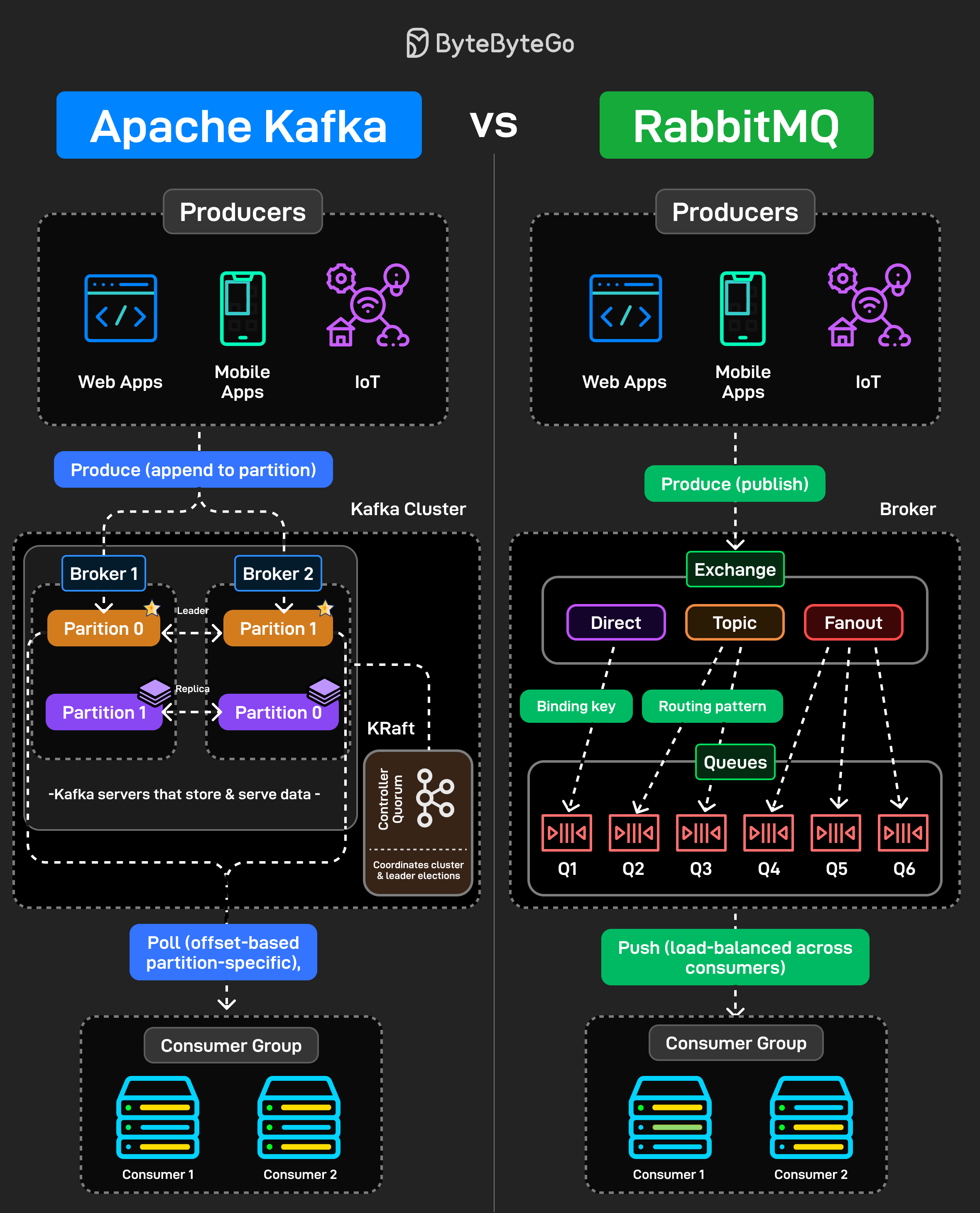
Kafka는 분산 로그입니다. Producer가 파티션에 메시지를 추가합니다. 그 메시지들은 소비 여부와 관계없이 보존 정책에 따라 유지됩니다. Consumer는 offset을 사용하여 자신의 속도에 맞게 메시지를 가져갑니다. 되감기, 재생, 전체 재처리가 가능합니다. 여러 Consumer가 동일한 데이터를 독립적으로 필요로 하는 고처리량 이벤트 스트리밍을 위해 설계되었습니다.
RabbitMQ는 메시지 브로커입니다. Producer가 exchange에 메시지를 발행합니다. 그 exchange들은 바인딩 키와 패턴(direct, topic, fanout)에 따라 큐로 라우팅합니다. 메시지는 Consumer에게 푸시되고 확인(acknowledge) 후 삭제됩니다. 작업 분배와 전통적인 메시징 워크플로우를 위해 구축되었습니다.
흔한 실수는 Kafka를 큐처럼 사용하거나 RabbitMQ를 이벤트 로그처럼 사용하는 것입니다. 이들은 서로 다른 사용 사례를 위해 만들어진 다른 도구입니다.
HTTP 마인드맵
HTTP는 HTTP/1.1에서 HTTP/2로, 그리고 이제 향상된 성능을 위해 UDP 기반 QUIC 프로토콜을 사용하는 HTTP/3로 발전해 왔습니다. 오늘날 HTTP는 브라우저와 API부터 스트리밍, 클라우드, AI 시스템까지 인터넷의 거의 모든 것의 근간입니다.
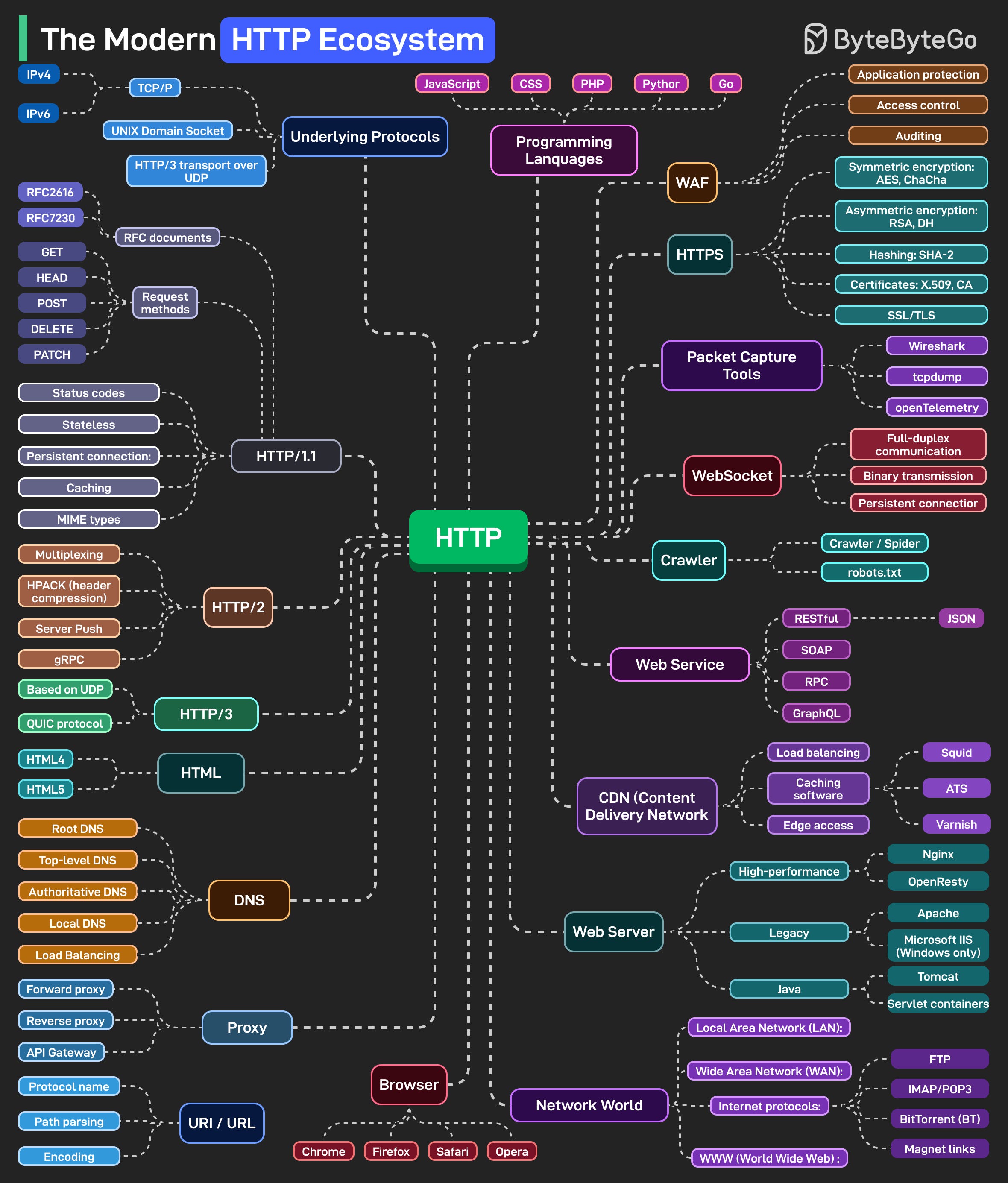
기반에는 underlying protocol이 있습니다. IPv4와 IPv6 트래픽을 위한 TCP/IP, 로컬 통신을 위한 Unix domain socket, TCP 대신 UDP를 사용하는 HTTP/3가 있습니다. 이것들이 HTTP가 작동하기 전에 실제 데이터 전송을 처리합니다.
보안은 모든 층을 감싸고 있습니다. HTTPS는 이제 선택 사항이 아닙니다. WebSocket은 실시간 연결을 지원합니다. 웹 서버가 워크로드를 관리합니다. CDN은 콘텐츠를 전 세계에 분산시킵니다. DNS는 모든 것을 IP로 해석합니다. 프록시(포워드, 리버스, API 게이트웨이)는 그 사이에서 트래픽을 라우팅하고, 필터링하고, 보호합니다.
웹 서비스는 다양한 형식으로 데이터를 교환합니다. JSON을 사용하는 REST, 엔터프라이즈 시스템을 위한 SOAP, 직접 호출을 위한 RPC, 유연한 쿼리를 위한 GraphQL이 있습니다. 크롤러와 봇은 경계를 설정하는 robots.txt 파일의 안내에 따라 웹을 인덱싱합니다.
네트워크 세계는 모든 것을 연결합니다. LAN, WAN, 그리고 파일 전송을 위한 FTP, 이메일을 위한 IMAP/POP3, P2P 통신을 위한 BitTorrent와 같은 프로토콜이 있습니다. 관측성을 위해 Wireshark, tcpdump, OpenTelemetry와 같은 패킷 캡처 도구를 통해 개발자들이 스택 전반의 성능, 지연 시간, 동작을 이해할 수 있습니다.
DNS 작동 원리
도메인 이름을 입력하고 엔터를 누르면, 그 웹페이지가 로드되기 전에 실제로 일어나는 일은 대부분의 사람들이 생각하는 것보다 복잡합니다. DNS는 인터넷의 전화번호부이며, 여러분이 하는 모든 요청은 여러 서버에 걸친 조회 체인을 트리거합니다.
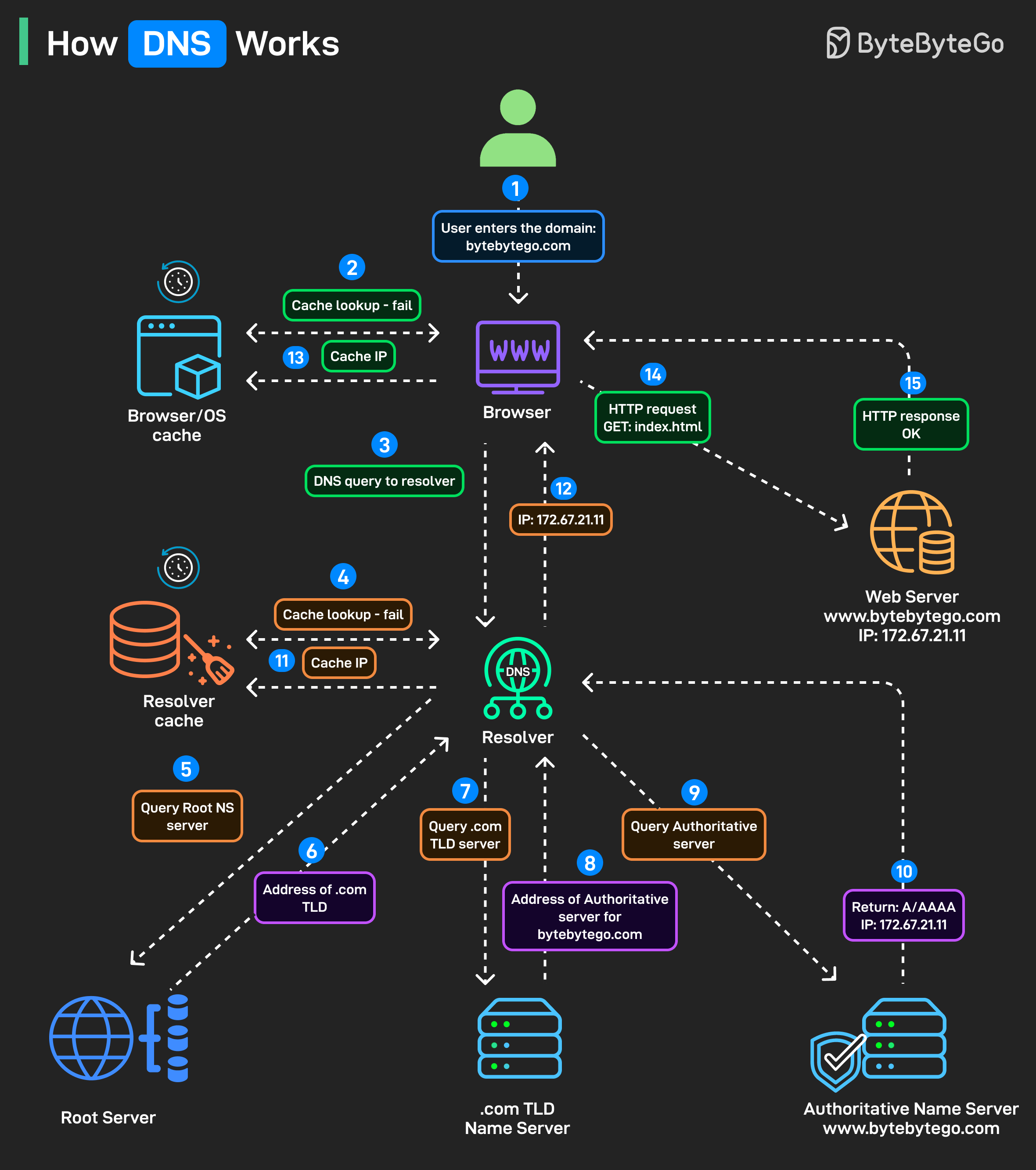
Step 1: 누군가 브라우저에 bytebytego.com을 입력하고 엔터를 누릅니다.
Step 2: 무엇이든 하기 전에, 브라우저는 캐시된 IP 주소를 찾습니다. 운영체제 캐시도 확인합니다.
Step 3: 캐시 미스가 발생하면 DNS 쿼리를 트리거합니다. 브라우저는 설정된 DNS resolver에 쿼리를 보내는데, 보통 ISP나 Google DNS, Cloudflare 같은 서비스에서 제공합니다.
Step 4: Resolver가 자체 캐시를 확인합니다.
Step 5-6: Resolver에 캐시된 답이 없으면, root 서버에 ".com은 어디서 찾을 수 있나요?"라고 물어봅니다. bytebytego.com의 경우, root 서버는 .com TLD 네임서버의 주소로 응답합니다.
Step 7-8: Resolver가 .com TLD 서버에 쿼리합니다. TLD 서버가 권한 있는 서버 주소를 반환합니다.
Step 9-10: 이 서버가 도메인을 IP 주소에 매핑하는 실제 A/AAAA 레코드를 가지고 있습니다. Resolver가 드디어 답을 얻습니다: bytebytego.com의 경우 172.67.21.11입니다.
Step 11-12: IP는 향후 조회를 위해 resolver 레벨에서 캐시되고, 브라우저에 반환됩니다.
Step 13-14: 브라우저는 이를 자체 향후 사용을 위해 저장하고, 해당 IP를 사용하여 실제 HTTP 요청을 만듭니다.
Step 15: 웹 서버가 요청된 콘텐츠를 반환합니다.
이 모든 것이 첫 페이지 로딩이 시작되기 전에 밀리초 단위로 일어납니다.
웹 서버가 실시간 업데이트를 제공할 수 있을까?
HTTP 서버는 자동으로 브라우저에 연결을 시작할 수 없습니다. 결과적으로 웹 브라우저가 시작하는 쪽입니다. HTTP 서버에서 실시간 업데이트를 받으려면 어떻게 해야 할까요?
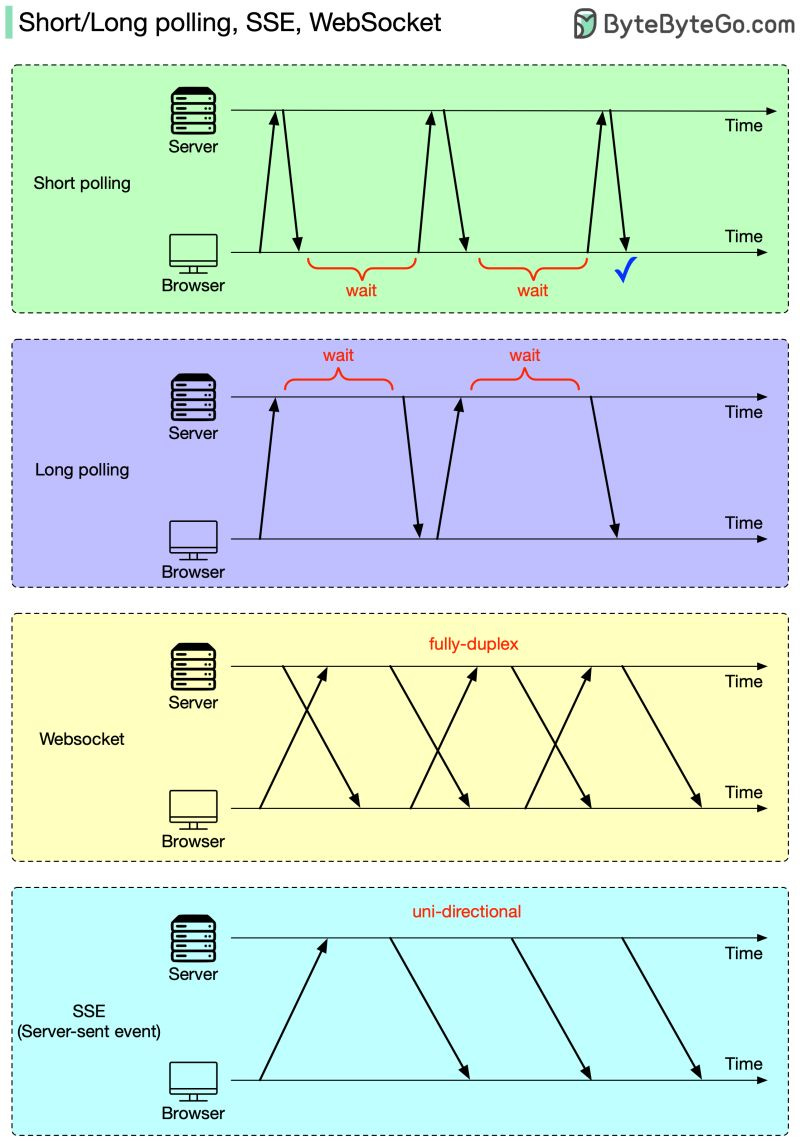
웹 브라우저와 HTTP 서버 모두 이 작업을 담당할 수 있습니다.
-
웹 브라우저가 주도하는 방식: short polling 또는 long polling. Short polling에서는 브라우저가 최신 데이터를 받을 때까지 재시도합니다. Long polling에서는 HTTP 서버가 새 데이터가 도착할 때까지 결과를 반환하지 않습니다.
-
HTTP 서버와 웹 브라우저가 협력하는 방식: WebSocket 또는 SSE(Server-Sent Event). 두 경우 모두 연결이 수립된 후 HTTP 서버가 브라우저에 직접 최신 데이터를 보낼 수 있습니다. 차이점은 SSE는 단방향이라서 브라우저가 서버에 새 요청을 보낼 수 없는 반면, WebSocket은 양방향이라서 브라우저가 계속 새 요청을 보낼 수 있다는 점입니다.
Related Articles
Thank you for reading.