Meta가 5% 더 나은 전환율을 위해 새로운 AI 기반 광고 모델을 구축한 방법
원문: How Meta Built a New AI-Powered Ads Model for 5% Better Conversions
면책사항: 이 게시물의 세부 사항은 Meta 엔지니어링 팀이 온라인으로 공유한 내용에서 파생되었습니다. 모든 기술적 세부 사항에 대한 공로는 Meta 엔지니어링 팀에 있습니다. 원문 기사 및 출처에 대한 링크는 게시물 끝의 참고 자료 섹션에 있습니다. 우리는 세부 사항을 분석하고 이에 대한 의견을 제공하려고 시도했습니다. 부정확하거나 누락된 내용이 있으면 댓글을 남겨주시면 최선을 다해 수정하겠습니다.
Meta가 2025년 2분기에 새로운 Generative Ads Model(GEM)이 Instagram에서 광고 전환율을 5% 증가시키고 Facebook Feed에서 3% 증가시켰다고 발표했을 때, 이 수치는 소박해 보였을 수 있습니다.
그러나 Meta의 규모에서 이러한 백분율은 수십억 달러의 추가 수익으로 전환되며 AI 기반 광고가 작동하는 방식의 근본적인 변화를 나타냅니다.
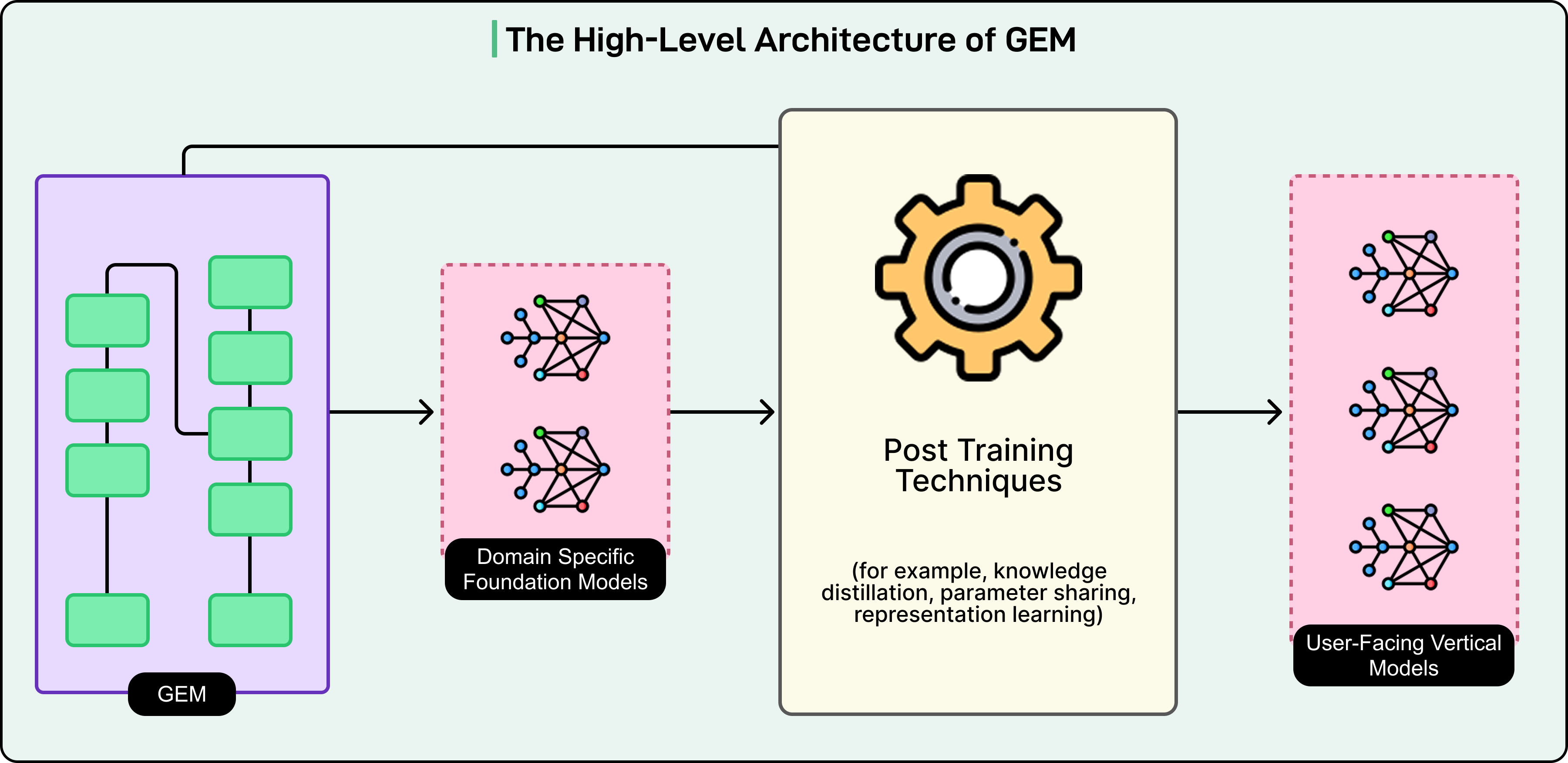
GEM은 추천 시스템을 위해 구축된 가장 큰 foundation model입니다. GPT-4나 Claude와 같은 대규모 언어 모델에 일반적으로 사용되는 규모로 훈련되었습니다. 그러나 여기에 역설이 있습니다. GEM은 너무 강력하고 계산 집약적이어서 Meta는 실제로 사용자에게 광고를 제공하는 데 직접 사용할 수 없습니다.
대신, 회사는 더 작고 빠른 모델이 계산 비용을 물려받지 않고도 GEM의 지능으로부터 이점을 얻을 수 있도록 하는 teacher-student 아키텍처를 개발했습니다.
이 글에서는 Meta 엔지니어링 팀이 GEM을 구축한 방법과 그들이 극복한 과제를 살펴봅니다.
GEM이 해결하는 핵심 문제
매일 수십억 명의 사용자가 Facebook, Instagram 및 기타 Meta 플랫폼을 스크롤하며 수조 개의 잠재적 광고 노출 기회를 생성합니다. 각 노출은 결정 지점을 나타냅니다. 수백만 개의 가능성 중에서 이 특정 사용자에게 이 특정 순간에 어떤 광고를 표시해야 할까요? 이것을 잘못하면 관련 없는 광고에 광고주 예산을 낭비하고 사용자가 관심 없는 콘텐츠로 짜증나게 만듭니다. 이것을 올바르게 하면 관련된 모든 사람에게 가치를 창출합니다.
기존 광고 추천 시스템은 여러 가지 방식으로 이 문제에 어려움을 겪었습니다. 일부 시스템은 각 플랫폼을 별도로 취급했는데, 이는 Instagram에서의 사용자 행동에 대한 통찰이 Facebook에서의 예측에 정보를 제공할 수 없다는 것을 의미했습니다. 이러한 사일로화된 접근 방식은 귀중한 크로스 플랫폼 패턴을 놓쳤습니다. 다른 시스템은 모든 플랫폼을 동일하게 취급하려고 시도했는데, 사람들이 Instagram Stories와 상호 작용하는 방식이 Facebook Feed를 탐색하는 방식과 매우 다르다는 사실을 무시했습니다. 두 접근 방식 모두 최적이 아니었습니다.
데이터 복잡성은 다음과 같은 방식으로 이러한 과제를 더욱 복잡하게 만듭니다:
- 클릭 및 전환과 같은 의미 있는 신호는 전체 노출 볼륨에 비해 극히 드뭅니다.
- 사용자 특성은 동적이며 지속적으로 변화합니다.
- 시스템은 텍스트, 이미지, 비디오 및 복잡한 행동 시퀀스를 포함한 멀티모달 입력을 처리해야 합니다.
- 기존 모델은 심각한 메모리 제한이 있어 일반적으로 사용자의 마지막 10~20개 작업만 고려했습니다.
GEM의 목표는 Meta의 전체 생태계에서 사용자를 전체적으로 이해하는 통합 인텔리전스를 만들고, 긴 행동 기록과 복잡한 크로스 플랫폼 패턴에서 학습하면서 각 특정 표면과 목표에 최적화하는 데 필요한 뉘앙스를 유지하는 것이었습니다.
GEM은 사용자를 어떻게 이해할까요?
GEM의 아키텍처는 세 가지 상호 보완적인 시스템을 통해 사용자 및 광고 정보를 처리하며, 각각은 예측 문제의 다른 측면을 처리합니다.
첫 번째 시스템은 Meta가 non-sequence features라고 부르는 것을 처리하는데, 이는 본질적으로 정적 속성과 그 조합입니다. 여기에는 나이 및 위치와 같은 사용자 인구통계, 사용자 관심사, 형식 및 크리에이티브 콘텐츠와 같은 광고 특성, 광고주 목표가 포함됩니다.
여기서 과제는 이러한 개별 특성을 아는 것뿐만 아니라 그것들이 어떻게 상호 작용하는지 이해하는 것입니다. 예를 들어, 25세 기술 직원은 일부 관심사를 공유하더라도 25세 교사와 매우 다른 구매 패턴을 가지고 있습니다. 시스템은 실제로 중요한 특성의 조합을 학습해야 합니다.
GEM은 더 깊은 상호 작용을 위해 수직으로 확장하고 더 넓은 특성 커버리지를 위해 수평으로 확장할 수 있는 stackable factorization machines를 갖춘 Wukong 아키텍처의 향상된 버전을 사용합니다. 이 아키텍처는 여러 스택 레이어를 통해 작동하며, 각 연속 레이어는 이전 레이어에서 발견한 더 간단한 패턴에서 점점 더 복잡한 패턴을 학습합니다. 예를 들어, 초기 레이어는 젊은 전문가가 기술 제품 광고에 잘 반응한다는 기본 패턴을 발견할 수 있습니다. 스택의 더 깊은 레이어는 이를 기반으로 도시 지역의 피트니스에 관심을 보이는 젊은 전문가가 특히 스마트 웨어러블 광고에 잘 반응한다는 것을 학습합니다. 훨씬 더 깊은 레이어는 이것을 더욱 세밀하게 다듬어, 이 조합이 특히 패션 요소보다는 데이터 추적 기능을 강조하는 광고에서 가장 잘 작동한다는 것을 발견할 수 있습니다.
두 번째 시스템은 사용자 행동의 타임라인을 캡처하는 sequence features를 처리합니다. 사용자의 행동은 고립되어 존재하지 않습니다. 그것들은 순서와 의미가 있는 이야기를 말합니다. 홈 운동 콘텐츠를 클릭한 다음 근처 헬스장을 검색한 다음 여러 헬스장 웹사이트를 본 다음 멤버십 비용을 조사한 사람은 분명히 특정 여정을 하고 있습니다. 기존 아키텍처는 시퀀스 길이가 증가함에 따라 계산 비용이 급격히 증가하기 때문에 긴 시퀀스를 효율적으로 처리하는 데 어려움을 겪었습니다.
GEM은 pyramid-parallel 구조로 이를 극복합니다. 하위 수준에서 행동 기록을 청크로 처리한 다음 중간 수준에서 해당 청크를 더 넓은 패턴으로 결합하고 마지막으로 최상위 수준에서 모든 것을 완전한 여정 이해로 합성하는 것으로 생각하십시오. 여러 청크를 순차적이 아닌 동시에 처리할 수 있어 효율성이 크게 향상됩니다.
여기서 획기적인 것은 규모입니다. GEM은 이제 가장 최근의 몇 가지가 아닌 수천 개의 과거 행동을 분석할 수 있습니다. 이 확장된 보기는 더 짧은 창이 단순히 캡처할 수 없는 패턴을 드러냅니다. 예를 들어 몇 달에 걸쳐 발전할 수 있는 캐주얼한 관심에서 진지한 구매 의도로의 진행과 같은 것입니다.
아래 다이어그램을 참조하세요:

세 번째 시스템인 InterFormer는 정적 프로필을 행동 타임라인과 연결하여 교차 특성 학습을 처리합니다. 여기서 GEM의 지능이 실제로 명확해집니다. 이전 접근 방식은 전체 행동 기록을 컴팩트한 요약 벡터로 압축했습니다(전체 소설을 단일 평점으로 줄이는 것과 같습니다). 이 압축은 불가피하게 여정에 대한 중요한 세부 사항을 잃습니다.
InterFormer는 interleaving 구조를 사용하여 다른 접근 방식을 취합니다. 행동 시퀀스를 순수하게 이해하는 데 집중하는 레이어와 해당 행동을 프로필 속성에 연결하는 레이어를 번갈아 가며 사용합니다.
- 첫 번째 시퀀스 레이어는 시간이 지남에 따라 피트니스에 대한 관심이 증가했다는 것을 식별할 수 있습니다.
- 그런 다음 첫 번째 교차 특성 레이어는 나이, 소득 및 위치 컨텍스트가 피트니스 관심이 무엇을 의미하는지 형성하는 방법을 고려합니다.
- 두 번째 시퀀스 레이어는 이러한 새로운 통찰력으로 행동을 다시 검사하고 직장 근처에 헬스장이 개장한 후 피트니스 연구가 강화되었음을 알 수 있습니다.
- 그런 다음 두 번째 교차 특성 레이어는 구매 의도와 타이밍에 대해 더 깊은 연결을 만듭니다.
이러한 교대 프로세스는 여러 레이어를 통해 계속되며, 각 사이클은 완전한 행동 기록에 대한 액세스를 잃지 않고 이해를 세밀하게 조정합니다.
GEM 사용의 실질적인 문제
GEM의 명백한 강점에도 불구하고 Meta는 GEM을 사용하는 데 근본적인 엔지니어링 과제에 직면했습니다.
GEM은 거대하며 수천 개의 GPU를 사용하여 장기간에 걸쳐 훈련되었습니다. 모든 광고 예측에 대해 GEM을 직접 실행하는 것은 불가능하게 느리고 비용이 많이 듭니다. 사용자가 Instagram을 스크롤할 때 시스템은 수십 밀리초 내에 광고 결정을 내려야 합니다. GEM은 단순히 수십억 명의 사용자에게 동시에 서비스를 제공하면서 그 속도로 작동할 수 없습니다.
Meta의 솔루션은 GEM이 실제로 프로덕션에서 광고를 제공하는 수백 개의 더 작고 빠른 Vertical Models(VMs)를 훈련시키는 마스터 교사 역할을 하는 teacher-student 아키텍처였습니다. 이러한 VM은 Instagram Stories 클릭 예측 또는 Facebook Feed 전환 예측과 같은 특정 컨텍스트에 특화되어 있습니다. 각 VM은 밀리초 내에 예측을 수행할 수 있을 만큼 가볍지만 독립적으로 훈련된 경우보다 훨씬 더 똑똑합니다. GEM에서 학습하기 때문입니다.
지식 전달은 두 가지 전략을 통해 발생합니다. Direct transfer는 VM이 유사한 데이터 및 목표를 가진 GEM이 훈련된 동일한 도메인에서 작동할 때 작동합니다. GEM은 이러한 모델을 직접 가르칠 수 있습니다. Hierarchical transfer는 VM이 GEM의 훈련 도메인과 상당히 다른 전문 영역에서 작업할 때 적용됩니다. 이러한 경우 GEM은 먼저 Instagram 또는 Facebook Marketplace와 같은 영역에 대한 중간 크기의 도메인별 foundation models를 가르칩니다. 그런 다음 이러한 도메인 모델은 훨씬 더 작은 VM을 가르칩니다. 지식은 레벨을 통해 아래로 흐르며 각 단계에서 적응되고 전문화됩니다.
Meta는 전달 효율성을 극대화하기 위해 세 가지 정교한 기술을 사용합니다:
- Student Adapter를 사용한 Knowledge distillation: Student 모델은 최종 예측뿐만 아니라 GEM의 추론 프로세스를 복제하는 것을 학습합니다. Student Adapter는 최근 ground-truth 데이터를 사용하여 GEM의 예측을 세밀하게 조정하고 타이밍 지연 및 도메인별 차이를 조정합니다.
- Representation learning: 교사와 학생 간에 공유된 개념 프레임워크를 만듭니다. GEM은 다양한 모델 크기에 걸쳐 잘 전달되는 방식으로 정보를 인코딩하는 것을 학습하며 광고 제공 중에 계산 오버헤드를 추가하지 않습니다.
- Parameter sharing: 이를 통해 VM은 GEM에서 특정 구성 요소를 선택적으로 직접 통합할 수 있습니다. 작은 VM은 빠른 속도를 유지하면서 복잡한 사용자 이해 작업을 위해 GEM의 정교한 구성 요소를 빌립니다.
이 세 가지 기술을 함께 사용하면 표준 knowledge distillation만 사용하는 것보다 두 배의 효율성을 달성합니다. 지속적인 개선 주기는 다음과 같이 작동합니다:
- 사용자는 실시간으로 빠른 VM과 상호 작용합니다
- 그들의 참여 데이터는 Meta의 데이터 파이프라인으로 다시 흐릅니다
- GEM은 이 새로운 데이터에 대해 주기적으로 재훈련하고, 업데이트된 지식은 post-training 기술을 통해 VM으로 전달되며,
- 개선된 VM이 프로덕션에 배포됩니다.
이 주기는 지속적으로 반복되며 GEM은 더 똑똑해지고 VM은 정기적인 인텔리전스 업데이트를 받습니다.
전례 없는 규모의 훈련
GEM 구축을 위해 Meta는 훈련 인프라를 처음부터 다시 구축해야 했습니다.
과제는 LLM 규모로 모델을 훈련하는 것이었지만 언어 생성이 아닌 근본적으로 다른 추천 작업을 위한 것이었습니다. 회사는 16배 더 많은 GPU를 사용하면서 효과적인 훈련 처리량을 23배 증가시키고 동시에 하드웨어 효율성을 1.43배 향상시켰습니다.
이를 위해서는 여러 영역에 걸친 혁신이 필요했습니다. Multi-dimensional parallelism은 수천 개의 GPU가 함께 작동하는 방식을 조율하여 Hybrid Sharded Distributed Parallel과 같은 기술을 사용하여 모델의 dense 구성 요소를 분할하면서 embedding tables와 같은 sparse 구성 요소를 data 및 model parallelism의 조합을 통해 처리합니다. 목표는 모든 GPU가 다른 GPU로부터의 통신을 기다리는 최소한의 유휴 시간으로 바쁘게 유지되도록 하는 것이었습니다.
시스템 수준 최적화는 GPU 활용도를 더욱 높였습니다:
- 가변 길이 사용자 시퀀스를 위해 설계된 맞춤형 GPU 커널로, 메모리 대역폭 병목 현상을 줄이기 위해 작업을 융합합니다.
- PyTorch 2.0 그래프 수준 컴파일은 activation checkpointing 및 operator fusion과 같은 최적화를 자동화합니다.
- 정확도에 영향을 주지 않고 footprint를 줄이는 FP8 quantization을 포함한 메모리 압축.
- 주요 계산 리소스를 소비하지 않고 GPU 간 통신을 처리하는 NCCLX communication collectives.
효율성 향상은 원시 훈련 속도를 넘어 확장되었습니다.
Meta는 trainer initialization, data reader 설정 및 checkpointing의 최적화를 통해 작업 시작 시간을 5배 단축했습니다. 지능형 캐싱 전략을 사용하여 PyTorch 2.0 컴파일 시간을 7배 단축했습니다. 이것들은 사소한 세부 사항처럼 보일 수 있지만 수백만 달러의 계산 리소스 비용이 드는 모델을 훈련할 때 효율성 향상의 모든 백분율 포인트가 엄청나게 중요합니다.
결과는 GEM에서 빠르게 반복할 수 있는 훈련 시스템으로, 이전 인프라로는 불가능했던 속도로 새로운 데이터 및 아키텍처 개선을 통합합니다. 이를 통해 Meta는 대규모 투자를 가치 있게 만들 정도로 비용을 제어하면서 GEM을 추천 AI의 최전선에 유지할 수 있습니다.
결론
Meta의 GEM 로드맵은 현재 기능을 훨씬 넘어 확장됩니다.
다음 주요 진화는 GEM이 텍스트, 이미지, 오디오 및 비디오를 별도의 입력 스트림으로 취급하는 대신 함께 처리하는 진정한 multimodal learning을 포함합니다. 이를 통해 모든 콘텐츠 유형에 걸쳐 사용자 선호도와 광고 크리에이티브 효과에 대한 훨씬 더 풍부한 이해가 가능해집니다. 회사는 또한 시스템이 간단한 경우를 더 효율적으로 처리하면서 어려운 예측에 더 많은 계산 리소스를 동적으로 할당할 수 있도록 하는 inference-time scaling을 탐구하고 있습니다.
아마도 가장 야심차게도 Meta는 동일한 기본 인텔리전스를 사용하여 유기적 콘텐츠와 광고를 모두 순위 매기는 통합 engagement model을 구상합니다. 이것은 광고가 소셜 피드에 통합되는 방식을 근본적으로 변경하여 광고가 방해가 아닌 자연스러운 콘텐츠 추천처럼 느껴지는 더 원활한 경험을 잠재적으로 생성할 것입니다. 광고주 측면에서 GEM의 인텔리전스는 AI 시스템이 최소한의 인간 개입으로 더 나은 결과를 달성하면서 캠페인을 관리하고 최적화할 수 있는 더 정교한 agentic automation을 가능하게 합니다.
참고 자료:
Thank you for reading.