$250만 달러의 논문
최근 24세의 연구자 Matt Deitke는 Meta의 Superintelligence Lab으로부터 2억 5천만 달러의 제안을 받았습니다. 이 제안의 정확한 세부사항은 공개되지 않았지만, 많은 사람들은 그의 멀티모달 모델 작업, 특히 Molmo라는 논문이 중요한 역할을 했다고 믿고 있습니다. Molmo는 폐쇄적인 독점 시스템에 의존하지 않고 처음부터 강력한 비전 언어 모델을 구축하는 방법을 보여주기 때문에 두드러집니다. 이는 대부분의 오픈 모델이 간접적으로 학습 데이터를 위해 비공개 API에 의존하는 환경에서 드문 일입니다.
이 글은 Molmo가 무엇인지, 왜 중요한지, 그리고 비전 언어 모델링의 오랜 문제를 어떻게 해결하는지 설명합니다. 또한 Molmo를 독특하게 만드는 데이터셋, 학습 방법, 아키텍처 결정을 살펴봅니다.
Molmo가 해결하는 핵심 문제
Vision Language Model, 즉 VLM은 GPT-4o나 Google Gemini와 같이 이미지와 텍스트를 함께 이해할 수 있는 시스템입니다. 우리는 이들에게 사진을 설명하고, 객체를 식별하고, 장면에 대한 질문에 답하거나, 시각적 및 텍스트 이해가 모두 필요한 추론을 수행하도록 요청할 수 있습니다.
아래 다이어그램을 참조하세요:
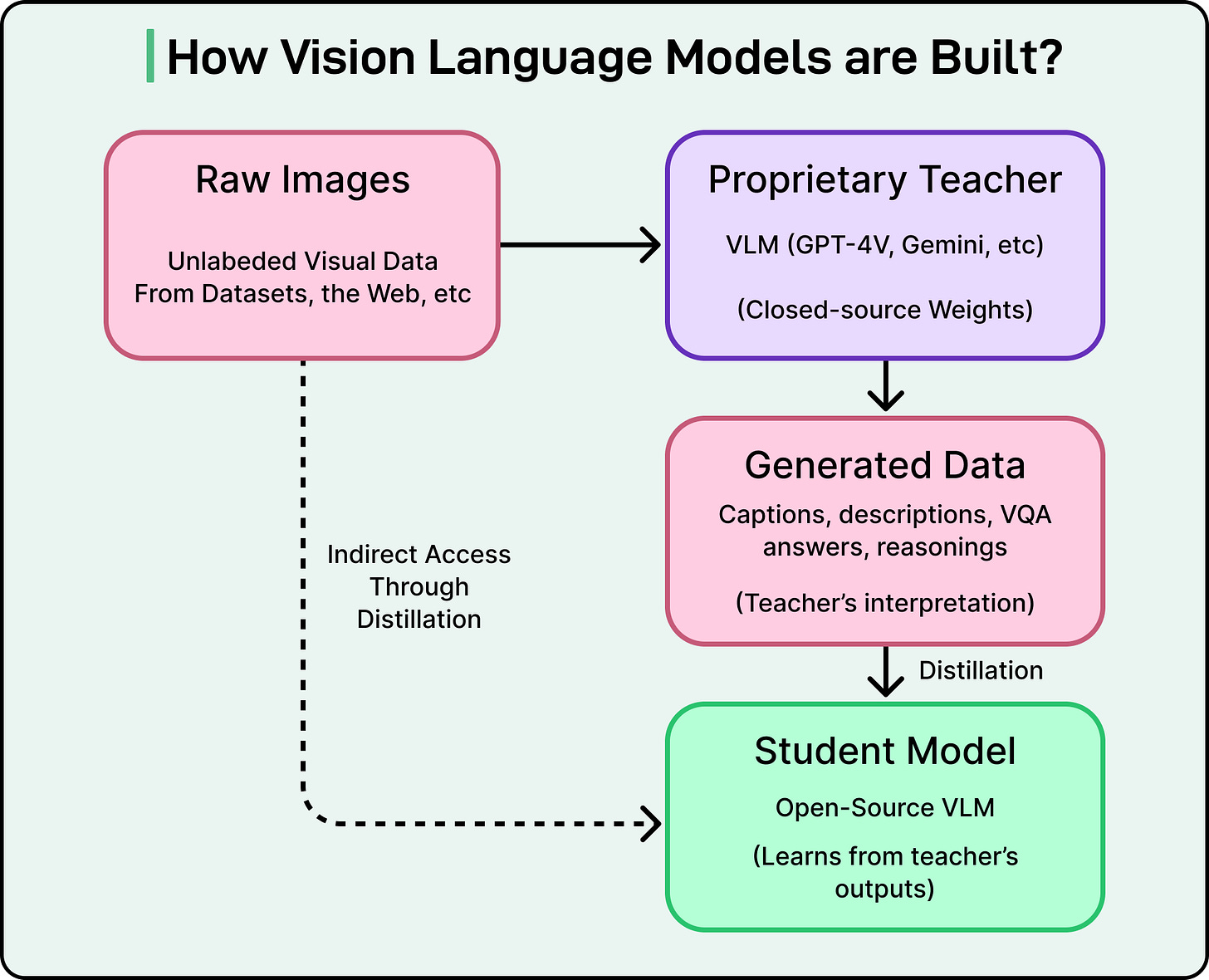
오늘날 많은 오픈 웨이트 VLM이 존재하지만, 대부분은 증류(distillation)라는 학습 접근 방식에 의존합니다. 증류에서는 더 작은 학생 모델이 더 큰 교사 모델의 출력을 모방하여 학습합니다.
일반적인 프로세스는 다음과 같습니다:
- 교사가 이미지를 봅니다.
- "빨간 소파에 앉아 있는 검은 고양이"와 같은 출력을 생성합니다.
- 연구자들이 이러한 출력을 수집합니다.
- 학생은 교사의 답변을 재현하도록 학습됩니다.
개발자는 GPT-4 Vision과 같은 독점 모델을 사용하여 수백만 개의 캡션을 생성한 다음, 이러한 캡션을 "오픈" 모델의 학습 데이터로 사용할 수 있습니다. 이 접근 방식은 대규모 인간 레이블링을 피하기 때문에 빠르고 저렴합니다. 그러나 몇 가지 심각한 문제를 야기합니다.
- 첫 번째 문제는 결과가 진정으로 오픈되지 않는다는 것입니다. 학생 모델이 비공개 API의 레이블로 학습되었다면, 그 API 없이는 재현할 수 없습니다. 이것은 영구적인 의존성을 만듭니다.
- 두 번째 문제는 커뮤니티가 더 강력한 모델을 구축하는 방법을 배우지 못한다는 것입니다. 대신 폐쇄된 모델의 동작을 복사하는 방법을 배웁니다. 기본 지식은 잠겨 있습니다.
- 세 번째 문제는 성능이 제한된다는 것입니다. 학생 모델은 교사를 거의 능가하지 못하므로, 모델은 교사의 강점과 약점을 물려받습니다.
이것은 급우의 숙제를 베끼는 것과 비슷합니다. 순간에는 효과가 있을 수 있지만, 우리는 기본 기술을 얻지 못하며, 급우가 도움을 멈추면 우리는 막히게 됩니다.
Molmo는 이 순환을 깨기 위해 설계되었습니다. 기존 VLM에 의존하지 않는 데이터셋에서 전적으로 학습됩니다. 이를 가능하게 하기 위해 저자들은 Molmo 학습의 기초를 형성하는 인간이 구축한 데이터셋 모음인 PixMo도 만들었습니다.
PixMo 데이터셋
PixMo는 다른 비전 언어 모델을 사용하지 않고 만든 7개의 데이터셋 모음입니다. PixMo의 목표는 Molmo가 처음부터 학습될 수 있도록 VLM이 없는 고품질 데이터를 제공하는 것입니다.
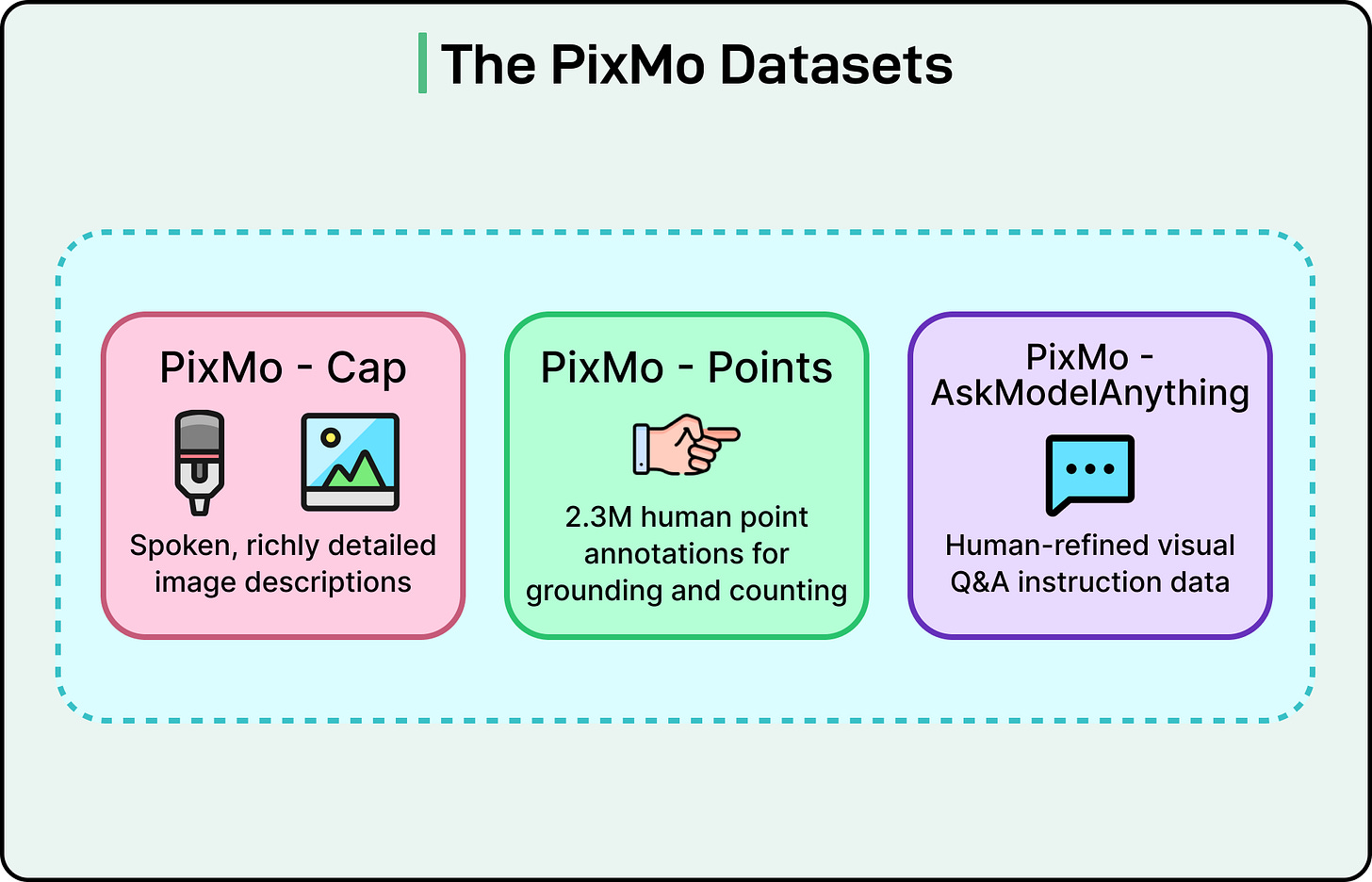
PixMo 데이터셋의 세 가지 주요 구성 요소가 있습니다:
PixMo Cap: 밀집 캡션
사전 학습을 위해 Molmo는 이미지에 대한 풍부한 설명이 필요했습니다. 긴 캡션을 입력하는 것은 느리고 피곤하므로, 연구자들은 간단하지만 강력한 아이디어를 사용했습니다. 그들은 주석자들에게 타이핑 대신 각 이미지에 대해 60~90초 동안 말하도록 요청했습니다.
사람들은 말할 때 자연스럽게 더 많이 설명합니다. 결과 캡션은 평균 196단어였습니다. 이것은 캡션이 평균 11단어인 COCO와 같은 일반적인 데이터셋보다 훨씬 더 상세합니다. 그런 다음 오디오가 전사되어 고품질 텍스트의 방대한 데이터셋을 생성했습니다. 오디오 녹음은 또한 실제 인간이 설명을 생성했다는 증거로 사용됩니다.
이러한 긴 캡션에는 조명, 배경 흐림, 객체 관계, 미묘한 시각적 단서, 심지어 예술적 스타일에 대한 관찰이 포함됩니다. 이것은 Molmo에게 짧은 캡션이 제공할 수 있는 것보다 이미지에 대한 더 깊은 이해를 제공합니다.
PixMo Points: 포인팅 및 그라운딩
PixMo Points는 프로젝트에서 가장 혁신적인 데이터셋일 수 있습니다. 팀은 230만 개 이상의 포인트 주석을 수집했습니다.
각 주석은 단순히 이미지의 특정 픽셀에 대한 클릭입니다. 포인팅이 바운딩 박스나 세그멘테이션 마스크를 그리는 것보다 빠르기 때문에, 데이터셋은 매우 빠르게 확장될 수 있었습니다.
포인트 주석은 Molmo에게 세 가지 중요한 능력을 가르칩니다:
- 객체를 가리키기
- 각각을 가리켜 객체를 세기
- 증거가 어디에 있는지 보여줌으로써 시각적 설명 제공
이 데이터셋은 모델이 언어를 정확한 공간 영역에 연결하는 데 도움이 되어, 이미지에서 이해를 근거로 삼는 데 더 나아집니다.
PixMo AskModelAnything: 지시 따르기
이 데이터셋은 이미지에 대한 질문과 답변 쌍을 제공합니다. 인간이 감독하는 프로세스를 통해 만들어졌습니다.
단계는 다음과 같습니다:
- 인간 주석자가 이미지에 대한 질문을 작성합니다.
- 언어 전용 LLM이 OCR 텍스트와 밀집 캡션을 기반으로 초안 답변을 생성합니다.
- 주석자가 답변을 검토합니다.
- 주석자는 이를 수락하거나, 거부하거나, 수정된 버전을 요청할 수 있습니다.
LLM은 텍스트만 보고 이미지 자체는 보지 않기 때문에, 데이터셋은 VLM이 없는 상태로 유지됩니다. 모든 답변은 인간이 승인합니다.
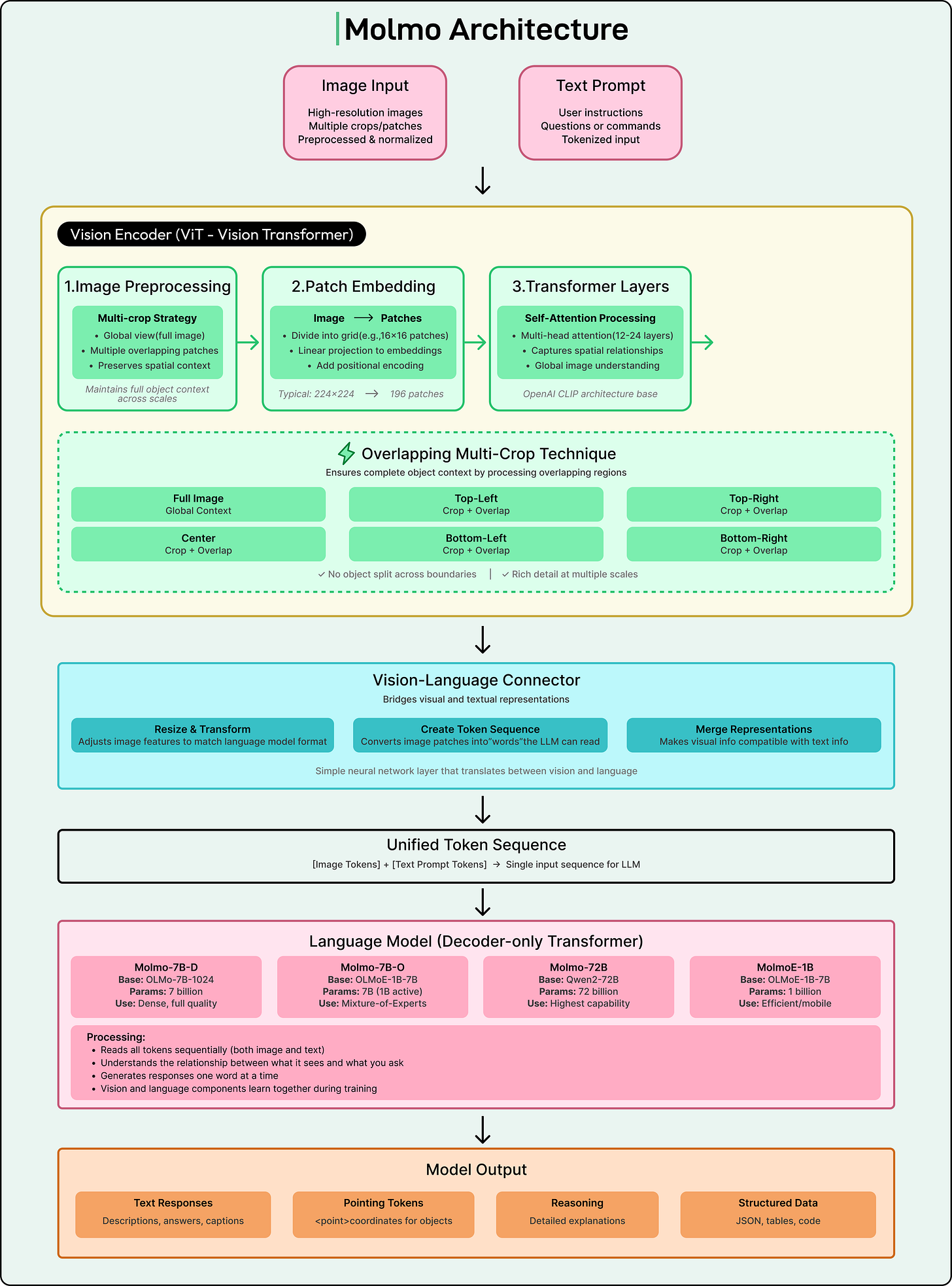
Molmo 아키텍처 및 학습
Molmo는 대부분의 비전 언어 모델에서 볼 수 있는 일반적인 구조를 사용합니다.
Vision Transformer가 비전 인코더 역할을 합니다. 대형 언어 모델이 추론과 텍스트 생성을 처리합니다. 커넥터 모듈이 시각적 및 언어 기능을 정렬하여 두 부분이 함께 작동할 수 있도록 합니다.
이 아키텍처는 표준이지만, Molmo의 학습 파이프라인에는 몇 가지 스마트한 엔지니어링 결정이 포함되어 있습니다.
중요한 아이디어 중 하나는 겹치는 다중 크롭 전략입니다. 고해상도 이미지는 한 번에 처리하기에 너무 크기 때문에 더 작은 정사각형 크롭으로 분할됩니다. 이것은 우연히 중요한 객체를 반으로 자를 수 있습니다. Molmo는 크롭이 겹치도록 하여 한 크롭의 경계에 있는 객체가 다른 크롭에 완전히 나타나도록 함으로써 이를 해결합니다. 이것은 모델이 완전한 객체를 더 일관되게 볼 수 있도록 돕습니다.
또 다른 개선 사항은 PixMo Cap의 품질에서 비롯됩니다. 많은 VLM은 노이즈가 많은 웹 데이터를 사용하는 긴 커넥터 학습 단계가 필요합니다. Molmo는 PixMo Cap 데이터셋이 직접 학습할 수 있을 만큼 강력하기 때문에 이 단계가 필요하지 않습니다. 이것은 학습을 더 간단하게 만들고 노이즈를 줄입니다.
저자들은 또한 여러 질문이 있는 이미지에 대한 효율적인 방법을 설계했습니다. 같은 이미지를 모델에 반복해서 공급하는 대신, 이미지를 한 번 인코딩한 다음 모든 질문을 단일 마스크 시퀀스로 처리합니다. 이것은 학습 시간을 절반 이상 줄입니다.
Molmo는 또한 사전 학습 중 텍스트 전용 드롭아웃을 사용합니다. 때때로 모델은 텍스트 토큰을 볼 수 없으므로 시각적 정보에 더 많이 의존해야 합니다. 이것은 언어 패턴을 통해 단순히 다음 토큰을 예측하는 것을 방지하고 진정한 시각적 이해를 강화합니다.
이러한 각 선택은 다른 선택을 지원하고 데이터셋에서 얻은 가치를 증가시킵니다.
Molmo의 장점
Molmo가 제공하는 주요 장점은 다음과 같습니다:
우수한 데이터의 강력한 이해
PixMo Cap의 음성 단어 캡션은 Molmo에게 더 풍부한 시각적 지식 기반을 제공합니다.
"프리스비를 잡는 갈색 개"와 같은 짧은 캡션에서 학습하는 대신, Molmo는 조명 조건, 카메라 각도, 배경 흐림, 객체 질감, 감정적 단서 및 암시된 동작을 언급하는 긴 설명을 봅니다. 이것은 더 깊고 상세한 시각적 표현으로 이어집니다.
포인팅을 통한 새로운 추론 능력
PixMo Points 데이터셋은 새로운 형태의 추론을 가능하게 합니다.
예를 들어, "이 이미지에 차가 몇 대 있습니까?"라는 질문을 받았을 때 많은 VLM은 단순히 숫자를 추측합니다. Molmo는 단계별 프로세스를 수행합니다. 각 차를 하나씩 가리킨 다음 최종 개수를 제공합니다. 이것은 추론을 가시적이고 확인하기 쉽게 만듭니다. 또한 오류를 수정하기 쉽게 만들고 로봇과 같은 픽셀 수준 지시가 필요한 미래 시스템으로의 문을 엽니다.
데이터와 학습 간의 더 나은 시너지
Molmo의 성공은 고품질 데이터와 해당 데이터를 최대화하기 위해 구축된 학습 파이프라인의 조합에서 비롯됩니다.
겹치는 크롭은 세부 사항을 보존하는 데 도움이 됩니다. 효율적인 배칭은 더 짧은 시간에 더 많은 지시 데이터를 사용합니다. 텍스트 전용 드롭아웃은 모델이 이미지에서 학습하도록 강제합니다. 고품질 캡션은 노이즈가 많은 학습 단계의 필요성을 줄입니다.
이러한 요소들은 서로를 강화하고 멀티모달 학습에 대한 더 깔끔하고 효과적인 접근 방식을 만듭니다.
결론
Molmo와 PixMo 프로젝트는 독점 시스템을 복사하지 않고도 강력한 비전 언어 모델을 구축할 수 있음을 보여줍니다.
이것은 고품질 인간 데이터가 폐쇄된 모델이 생성한 합성 데이터를 능가할 수 있음을 보여줍니다. 또한 사려 깊은 데이터셋 설계가 학습을 단순화하고 동시에 결과를 개선할 수 있는 방법을 강조합니다.
이러한 제1원리 접근 방식은 이 작업이 주요 AI 연구소로부터 강한 관심을 끈 이유 중 하나일 수 있습니다. 이것은 연구 커뮤니티가 강력하고 재현 가능하며 진정으로 오픈된 멀티모달 모델을 구축할 수 있는 방법을 제공합니다.
Thank you for reading.