EP166: Event Sourcing이란 무엇인가?
이번 주 시스템 설계 복습:
-
수조 개의 웹 페이지: Google은 어디에 저장할까? (YouTube 영상)
-
기업들은 어떻게 코드를 프로덕션에 배포할까?
-
Event Sourcing이란 무엇인가?
-
Data Lake 아키텍처는 어떻게 동작하는가?
-
Netflix는 어떻게 분산 카운터를 구축했는가?
-
TCP Handshake는 어떻게 동작하는가?
수조 개의 웹 페이지: Google은 어디에 저장할까?

기업들은 어떻게 코드를 프로덕션에 배포할까?
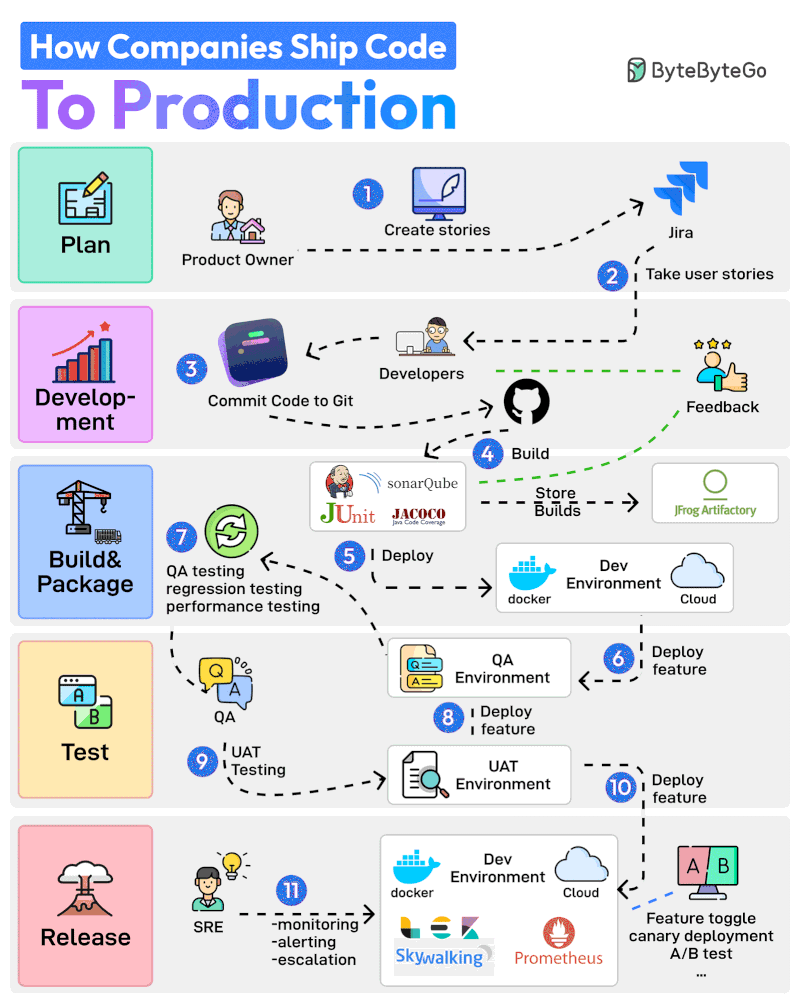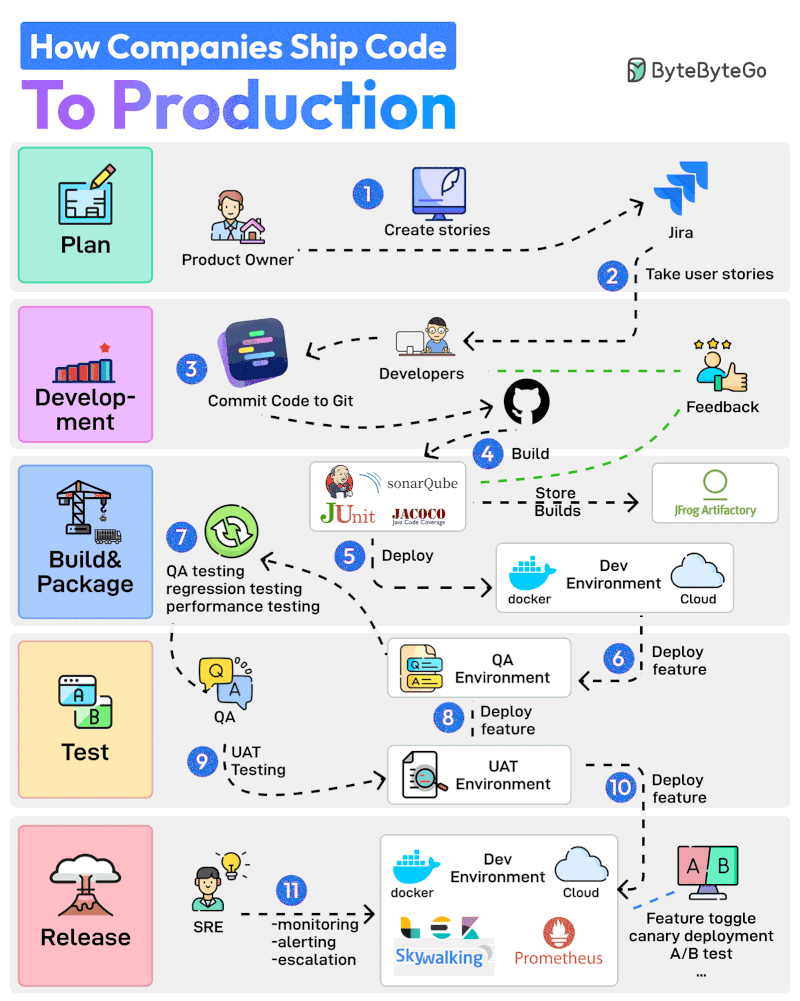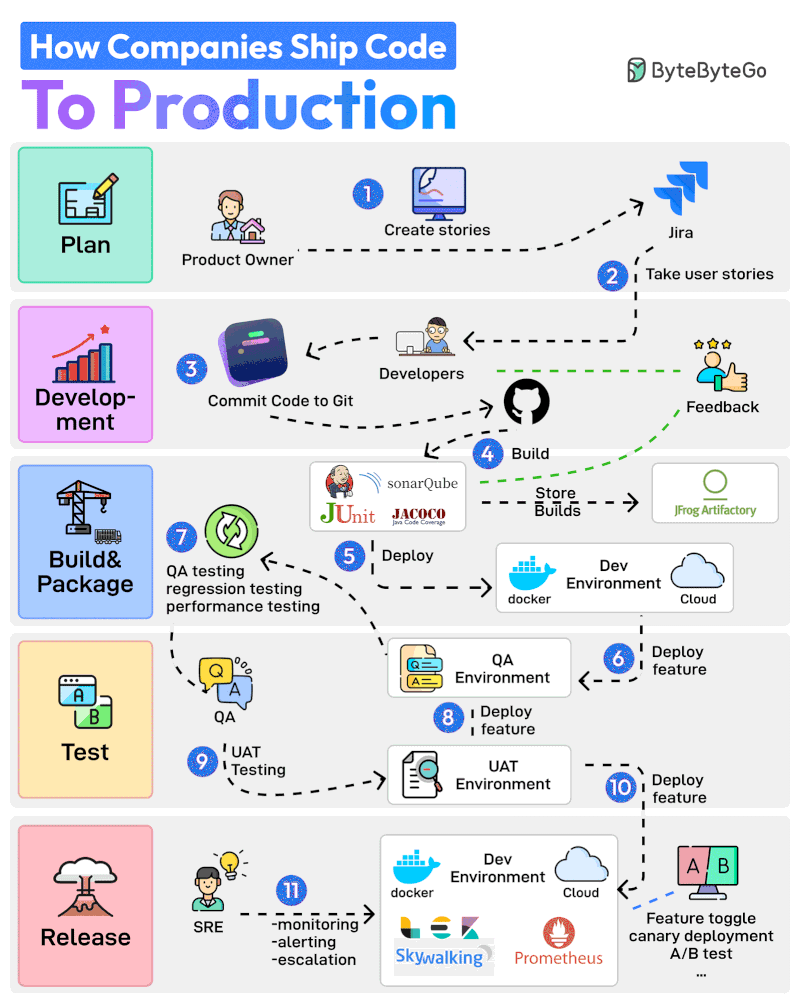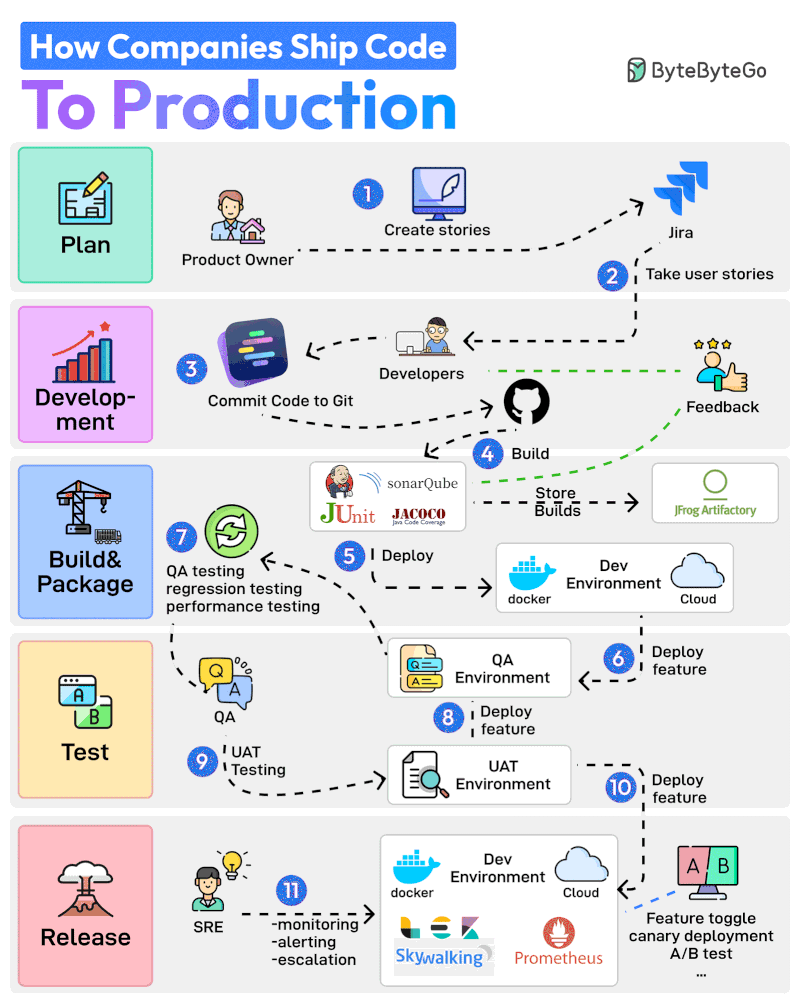
기획부터 프로덕션까지 11단계 프로세스를 살펴보겠습니다:
-
Product Owner가 Jira 같은 도구에서 User Story를 생성하며 전체 프로세스를 시작합니다.
-
개발팀이 Sprint Planning 활동을 수행하고 User Story를 스프린트에 추가합니다.
-
개발자들이 할당된 스토리를 작업합니다. 스토리가 완료되면 코드를 Git에 커밋하고 GitHub에 푸시합니다.
-
Jenkins가 코드를 빌드하고 JUnit, Jacoco, SonarQube 같은 테스트 및 품질 검사 도구를 통해 실행합니다.
-
빌드가 성공하면 JFrog 같은 Artifactory에 저장됩니다. Jenkins는 또한 Docker를 통해 빌드를 Dev Environment에 배포합니다.
-
다음으로 기능이 QA 환경에 배포됩니다. 여러 팀이 동일한 코드베이스에서 작업할 수 있으므로 여러 개의 QA 환경이 생성됩니다.
-
QA 팀이 특정 QA 환경을 사용하여 QA, 회귀, 성능 테스트 등 여러 유형의 테스트를 실행합니다.
-
QA 검증이 완료되면 기능이 UAT(User Acceptance Testing) 환경에 배포됩니다.
-
UAT 테스트는 기능이 사용자의 요구사항을 충족하는지 검증합니다.
-
UAT 테스트가 성공하면 빌드는 릴리스 후보가 됩니다. 특정 일정에 따라 프로덕션 환경에 배포됩니다.
-
SRE 팀이 ELK, Prometheus 같은 도구를 사용하여 프로덕션 환경을 모니터링하고 문제 발생 시 알림을 처리합니다.
Over to you: 이 프로세스에 추가할 단계가 있나요?
Event Sourcing이란 무엇인가? 일반적인 CRUD 설계와 어떻게 다른가?
아래 다이어그램은 일반적인 CRUD 시스템 설계와 Event Sourcing 시스템 설계를 비교한 것입니다. 주문 서비스를 예로 들어 설명합니다.
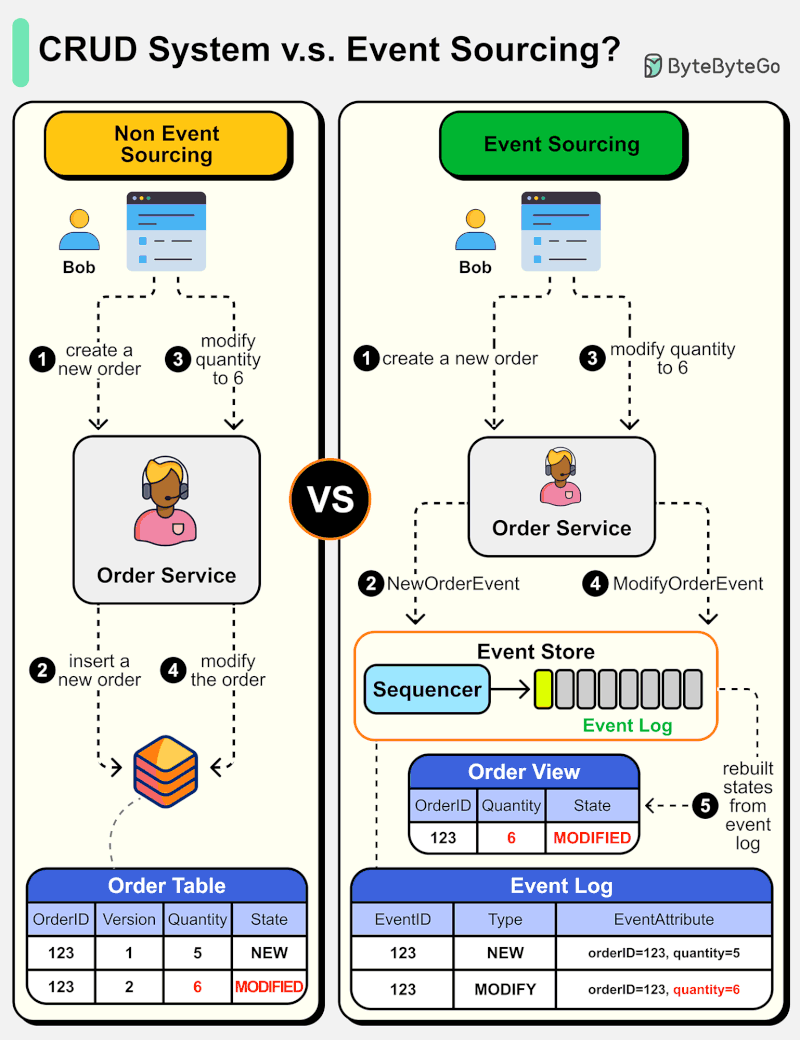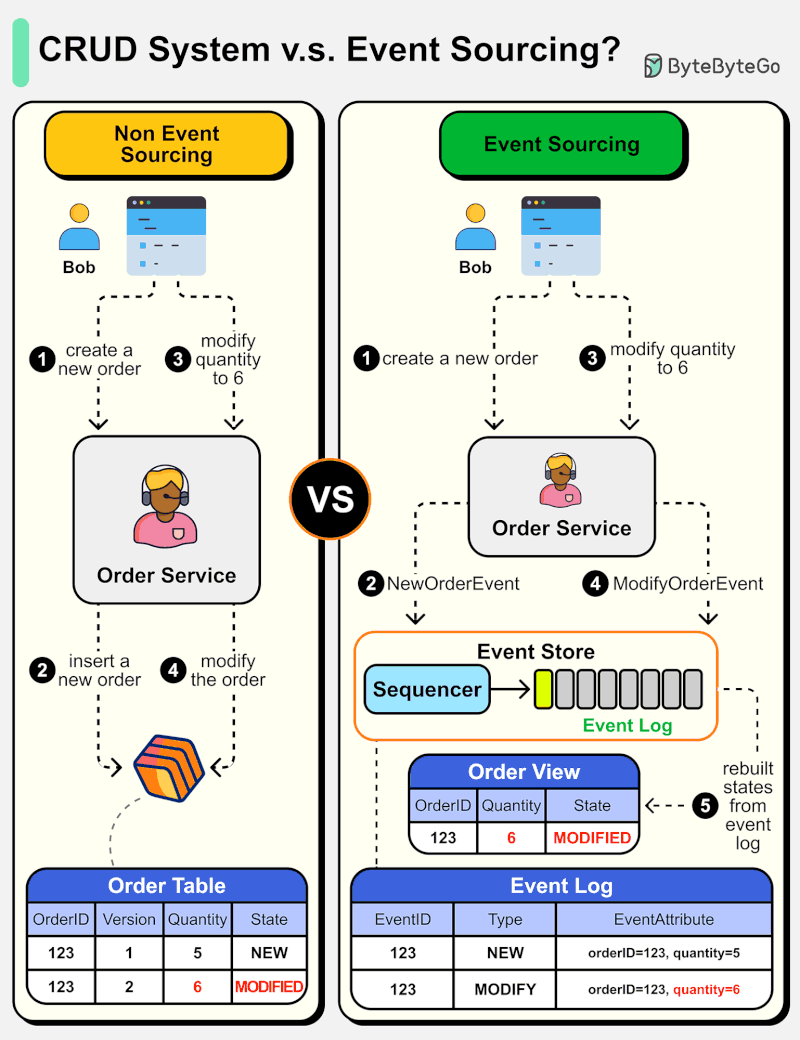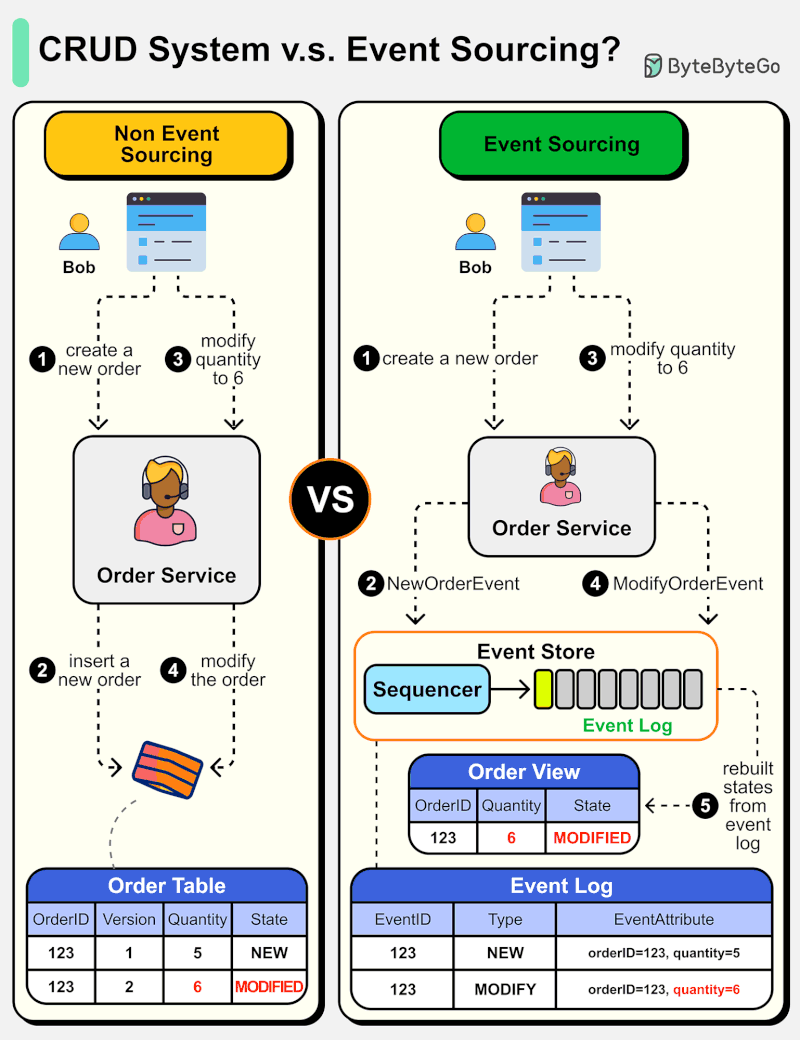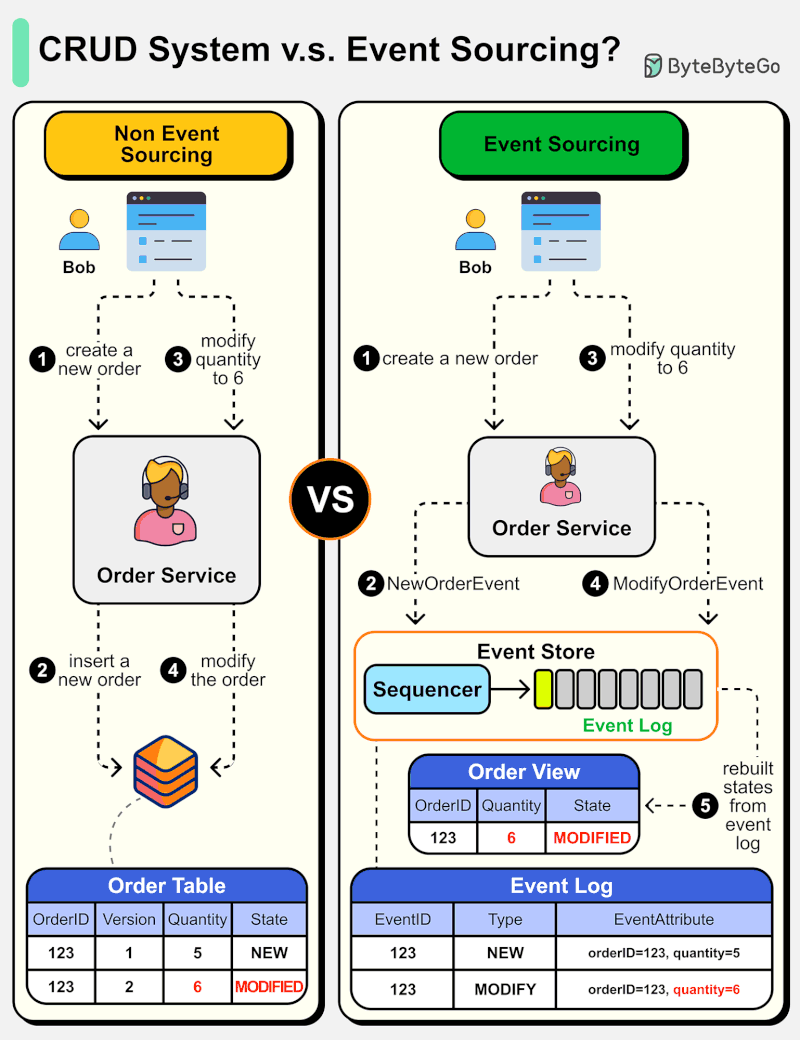
Event Sourcing 패러다임은 시스템을 결정론적(deterministic)으로 설계하는 데 사용됩니다. 이는 일반적인 시스템 설계의 철학을 바꾸는 것입니다.
어떻게 동작할까요? 데이터베이스에 주문 상태를 기록하는 대신, Event Sourcing 설계는 상태 변경을 유발하는 이벤트를 Event Store에 저장합니다. Event Store는 append-only 로그입니다. 이벤트는 순서를 보장하기 위해 증분 번호로 시퀀싱되어야 합니다. 주문 상태는 이벤트로부터 재구축되어 OrderView에서 유지될 수 있습니다. OrderView가 다운되더라도 진실의 원천(source of truth)인 Event Store에 항상 의존하여 주문 상태를 복구할 수 있습니다.
세부 단계를 살펴보겠습니다.
-
Non-Event Sourcing
-
Steps 1, 2: Bob이 제품을 구매하려 합니다. 주문이 생성되어 데이터베이스에 삽입됩니다.
-
Steps 3, 4: Bob이 수량을 5에서 6으로 변경하려 합니다. 주문이 새로운 상태로 수정됩니다.
-
-
Event Sourcing
-
Steps 1, 2: Bob이 제품을 구매하려 합니다. NewOrderEvent가 생성되고, 시퀀싱되어 eventID=321로 Event Store에 저장됩니다.
-
Steps 3, 4: Bob이 수량을 5에서 6으로 변경하려 합니다. ModifyOrderEvent가 생성되고, 시퀀싱되어 eventID=322로 Event Store에 저장됩니다.
-
Step 5: Order View가 주문 이벤트로부터 재구축되어 주문의 최신 상태를 보여줍니다.
-
Over to you: 어떤 유형의 시스템이 Event Sourcing 설계에 적합할까요? 업무에서 이 패러다임을 사용해 본 적이 있나요?
Data Lake 아키텍처는 어떻게 동작하는가?
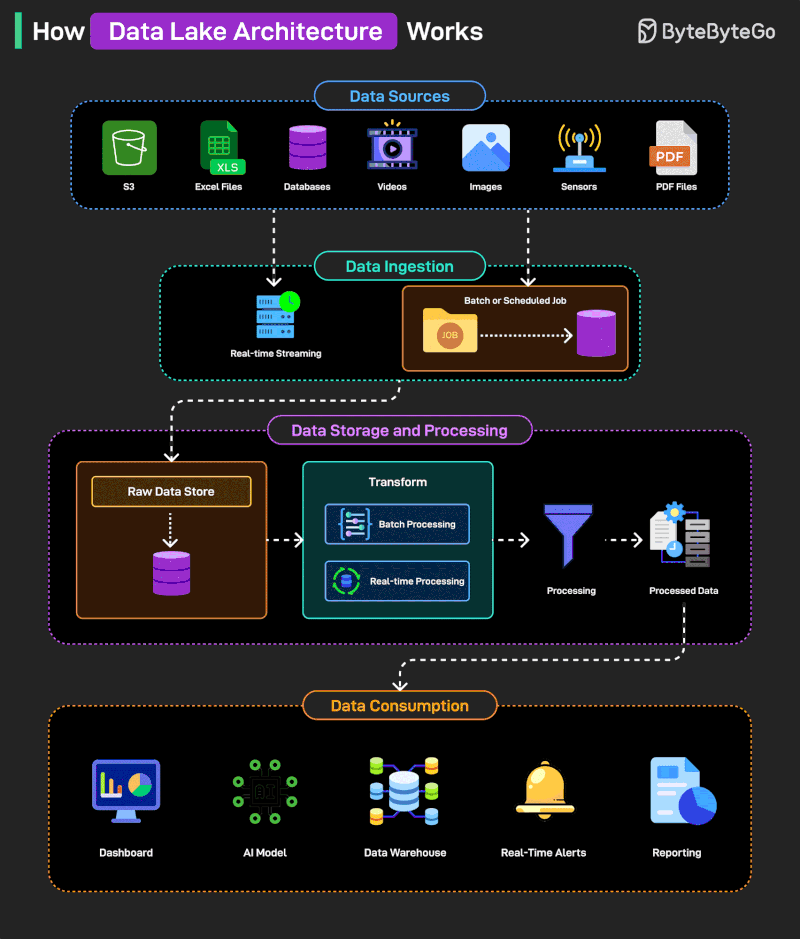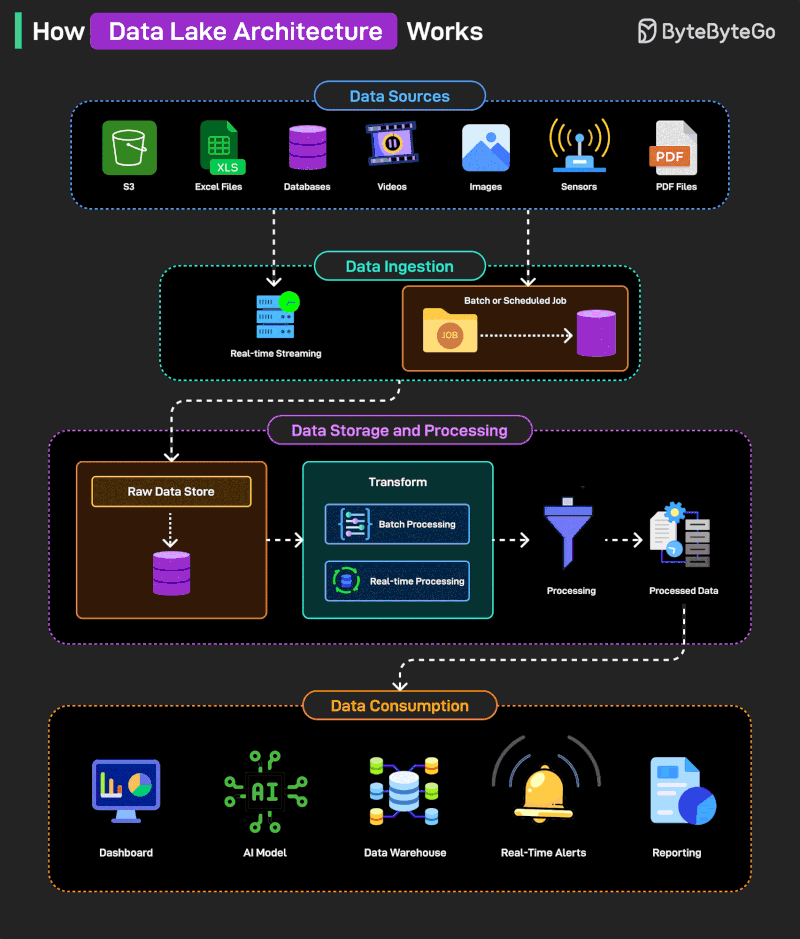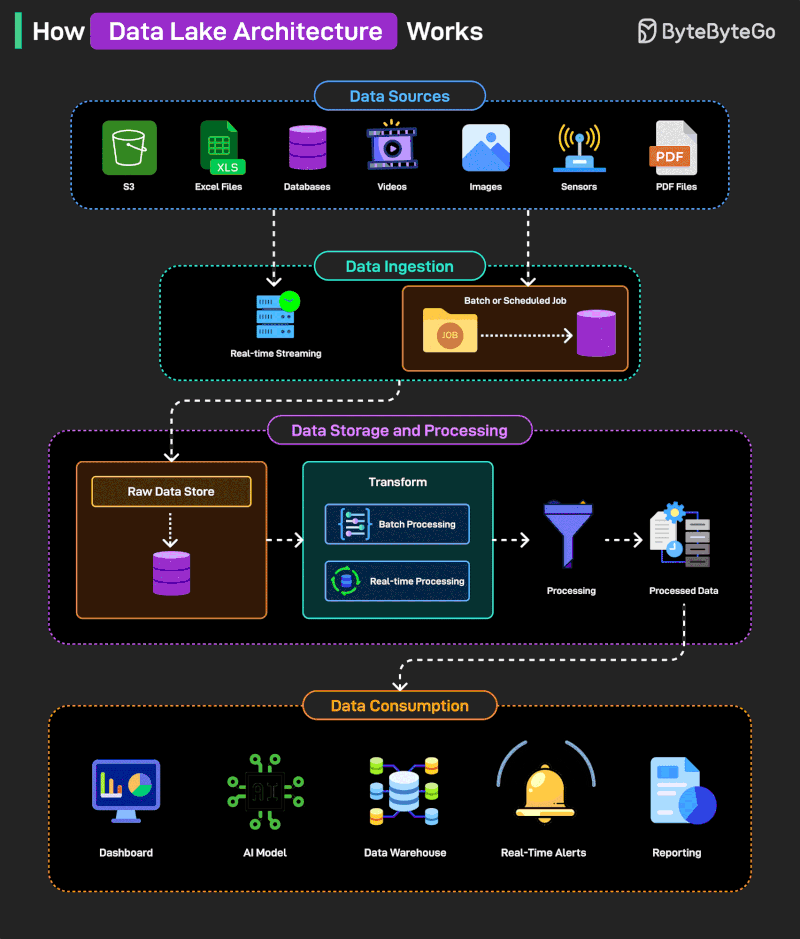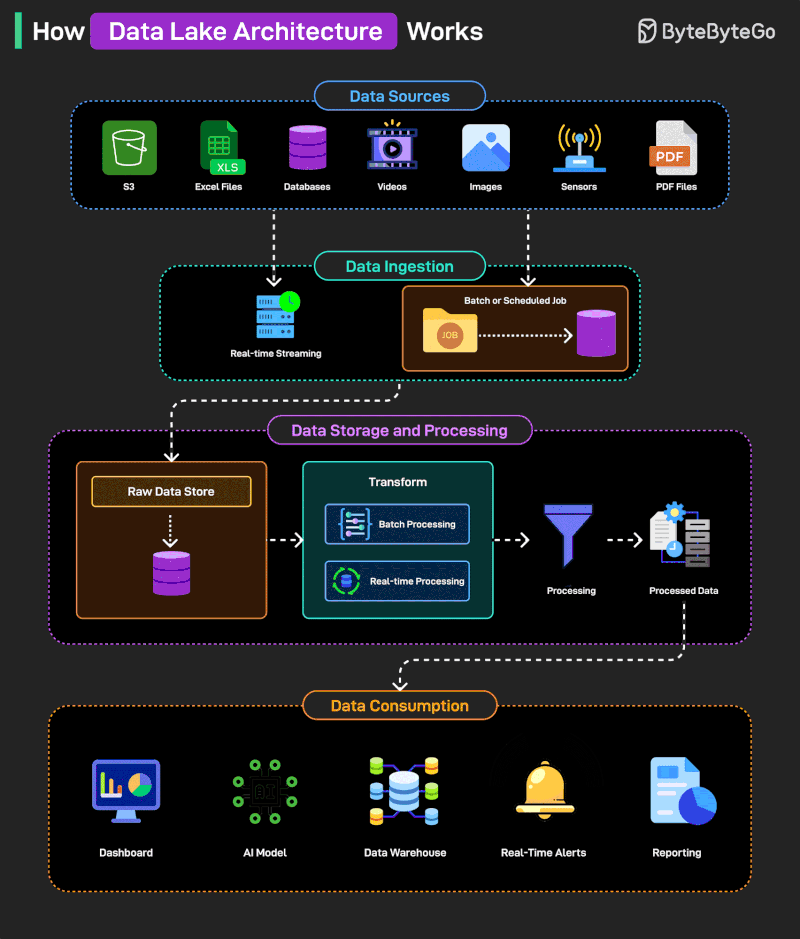
Data Lake는 대량의 구조화, 반구조화, 비구조화 데이터를 원시 형태로 저장하는 중앙 집중식 스토리지 시스템입니다. 조직이 데이터를 대규모로 저장하고 나중에 다양한 요구사항에 맞게 처리할 수 있게 해줍니다.
높은 수준에서 동작 방식은 다음과 같습니다:
-
S3, Excel 파일, 데이터베이스, 비디오, 이미지, 센서, PDF 등 다양한 소스의 데이터가 수집되어 ingestion 준비를 합니다.
-
Ingestion은 데이터 유형과 소스에 따라 실시간 스트리밍 또는 배치/스케줄 작업을 통해 이루어집니다.
-
Ingestion된 데이터는 변환이나 처리가 수행되기 전에 먼저 Raw Data Store에 저장됩니다.
-
그런 다음 데이터는 배치 또는 실시간 처리 시스템을 통해 정제, 변환되어 사용 준비가 됩니다.
-
처리된 데이터는 저장되어 다양한 도구와 플랫폼에서 다운스트림 소비가 가능하도록 준비됩니다.
-
최종 데이터 소비는 대시보드, AI 모델, 데이터 웨어하우스, 실시간 알림, 리포팅 시스템을 통해 이루어집니다.
Over to you: Data Lake 아키텍처를 더 잘 이해하기 위해 추가할 내용이 있나요?
Netflix는 어떻게 분산 카운터를 구축했는가?
Netflix의 분산 카운터는 시스템 설계를 배우기 위한 훌륭한 교과서입니다.
분산 카운터(Distributed Counter)는 이벤트 카운팅의 책임이 네트워크 내 여러 서버 또는 노드에 분산된 시스템입니다. Netflix는 실시간 의사결정과 인프라 최적화를 위해 여러 사용자 상호작용을 추적하고 측정해야 합니다.
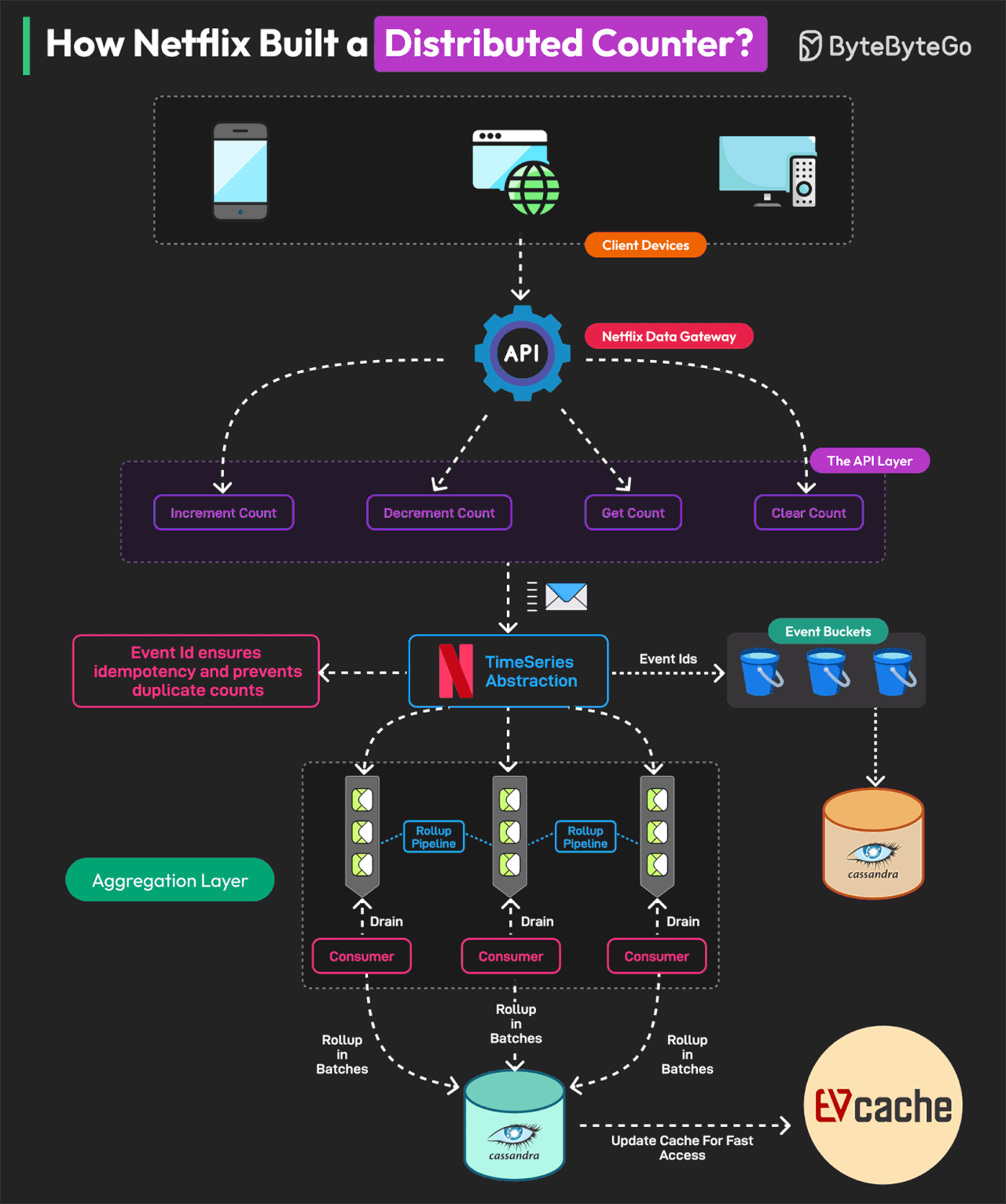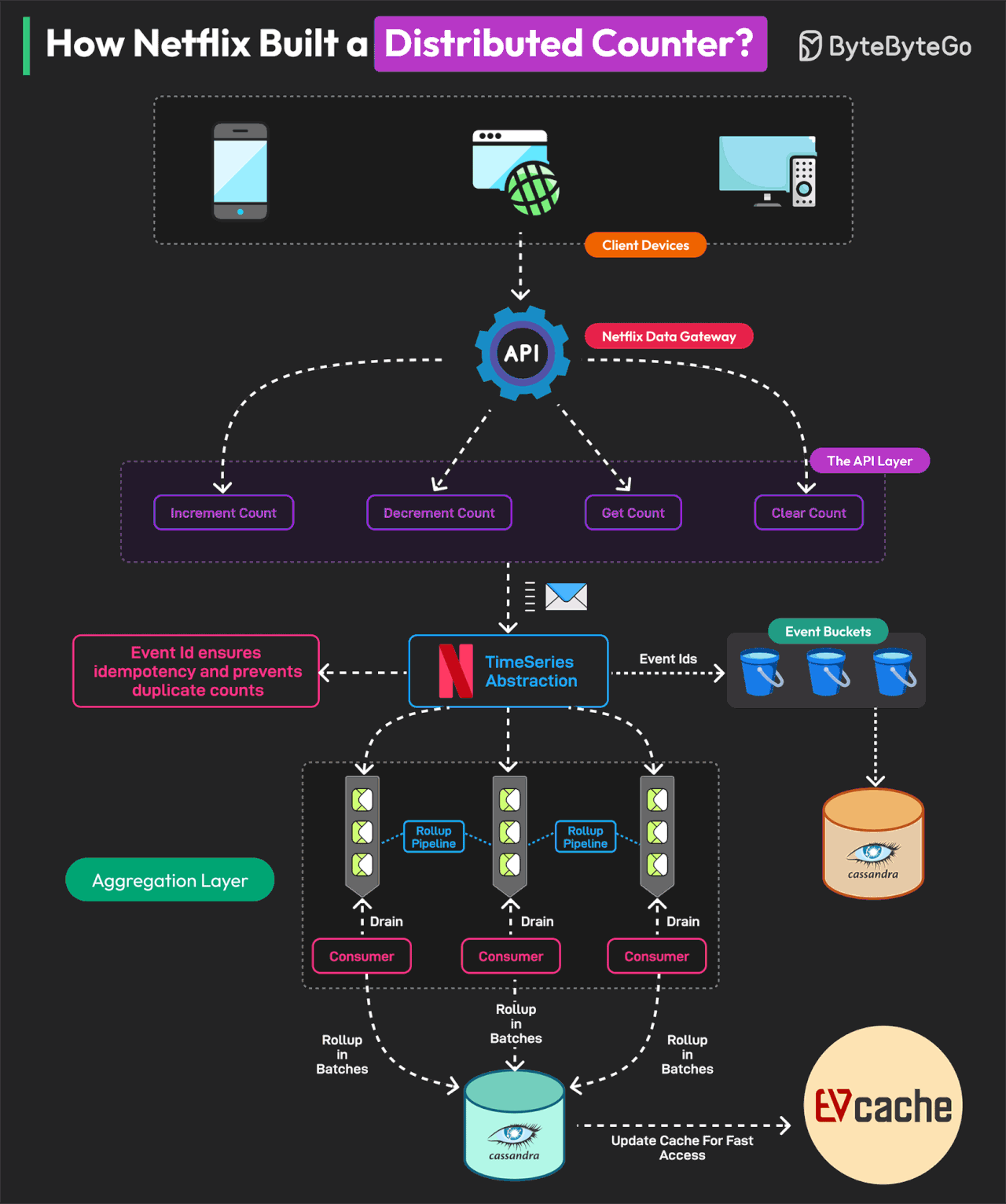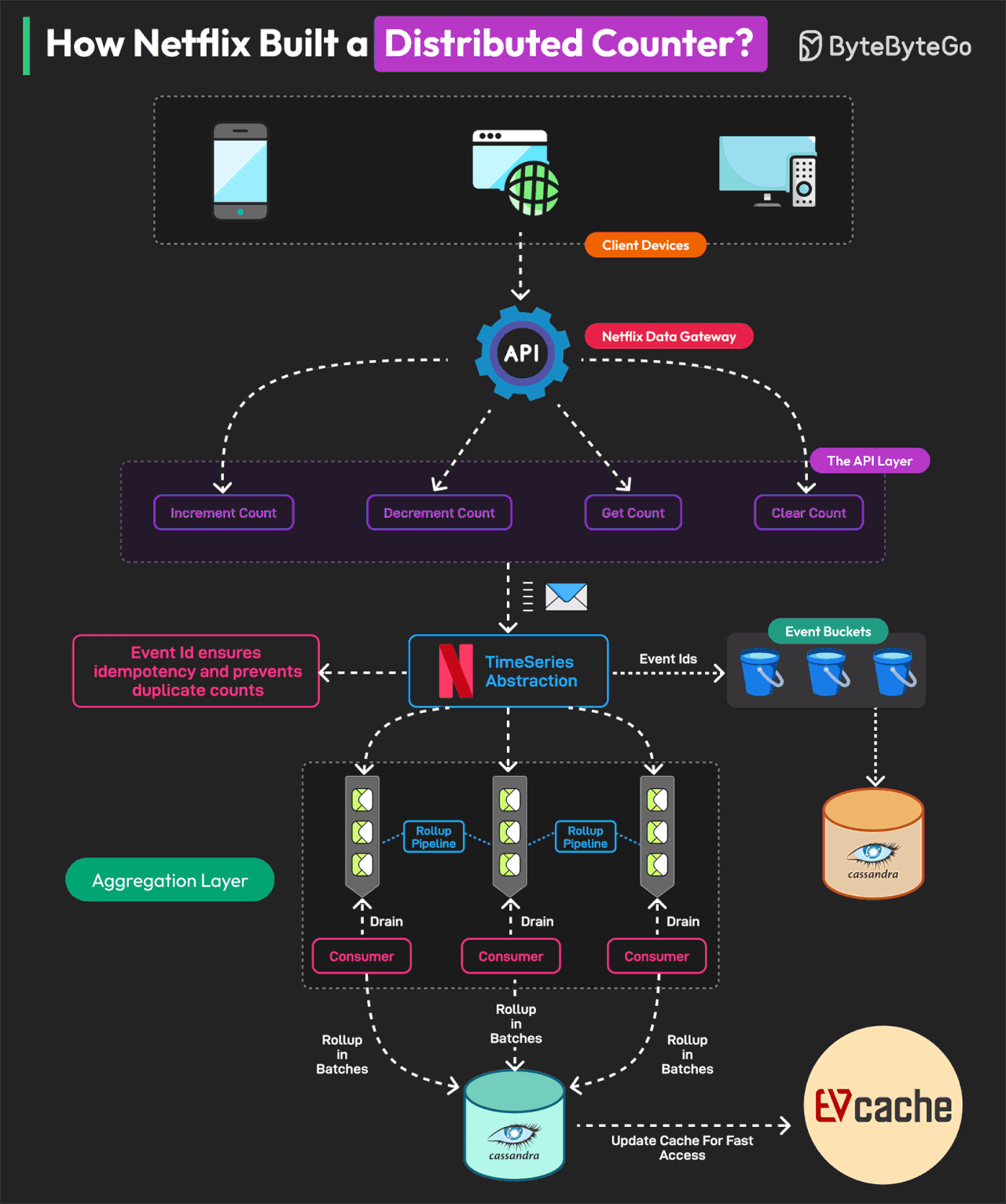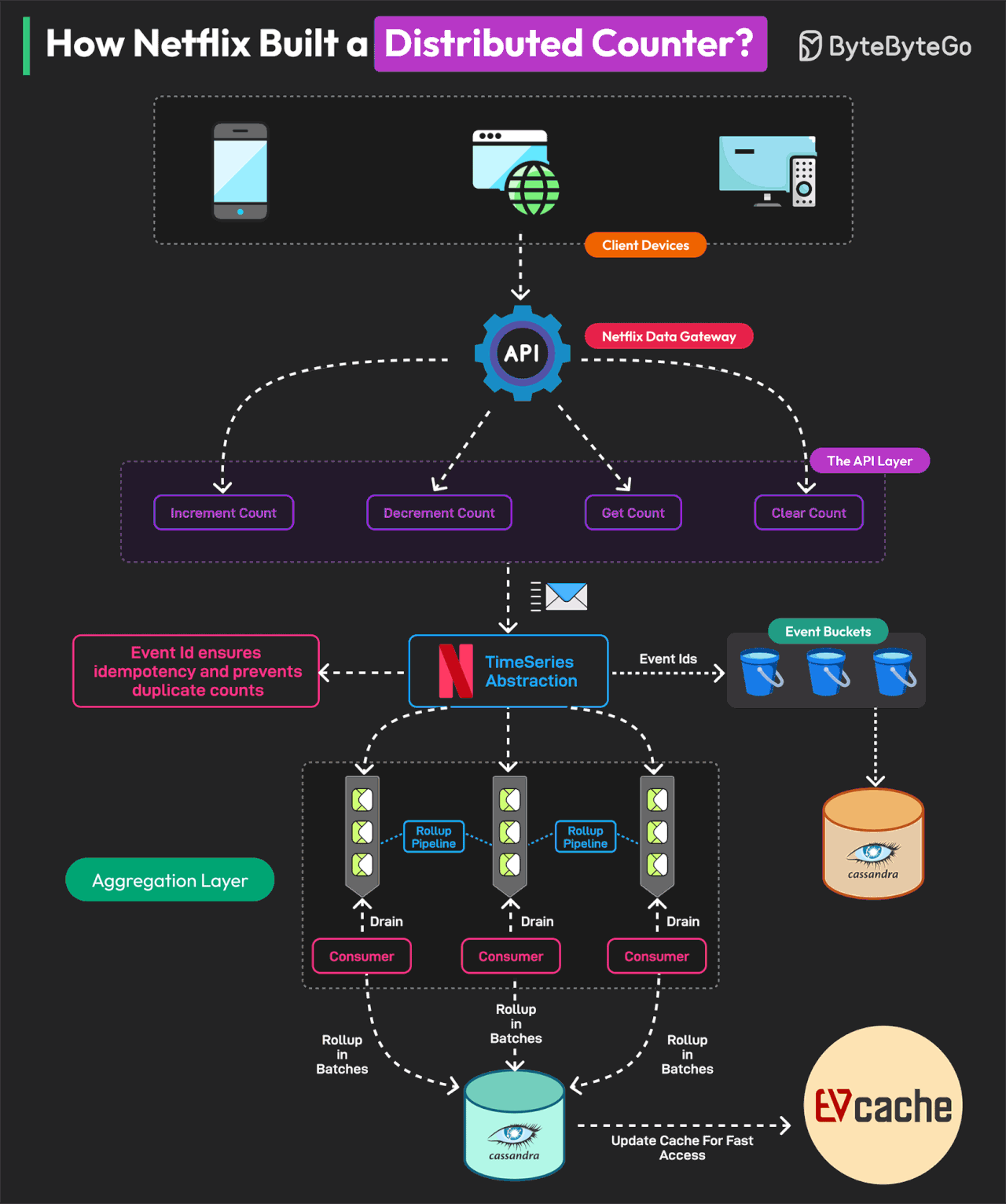
이를 위해 Netflix는 Distributed Counter Abstraction을 구축했습니다. Netflix의 Distributed Counter Abstraction은 4개의 주요 레이어로 운영되어 고성능, 확장성, eventual consistency를 보장합니다.
-
Client API Layer 사용자는 AddCount, GetCount, ClearCount 요청을 전송하여 시스템과 상호작용합니다. Netflix Data Gateway가 이러한 요청을 효율적으로 처리하고 라우팅합니다.
-
Event Logging and TimeSeries Storage 이벤트는 확장성을 위해 Netflix TimeSeries Abstraction에 저장됩니다. 각 이벤트는 멱등성(idempotency)을 보장하기 위해 Event ID로 태깅됩니다. 데이터베이스 경합을 피하기 위해 이벤트는 버킷이라고 알려진 시간 파티션으로 그룹화됩니다. 데이터는 Cassandra에 저장됩니다.
-
Rollup Pipeline or Aggregation Rollup Queue가 이벤트 변경사항을 수집하고 배치로 처리합니다. 집계는 불변 시간 윈도우에서 발생하여 정확한 rollup 계산을 보장합니다. 데이터는 eventual consistency를 위해 Cassandra Rollup Store에 저장됩니다.
-
Read Optimization (Cache & Query Handling) 집계된 카운터 값은 초고속 읽기를 위해 EVCache에 캐시됩니다. 캐시 값이 오래되면 백그라운드 rollup 새로고침이 이를 업데이트합니다. 이 모델을 통해 Netflix는 한 자릿수 밀리초 latency로 초당 75K 요청을 처리할 수 있습니다.
Reference: Netflix's Distributed Counter Abstraction
TCP Handshake는 어떻게 동작하는가?
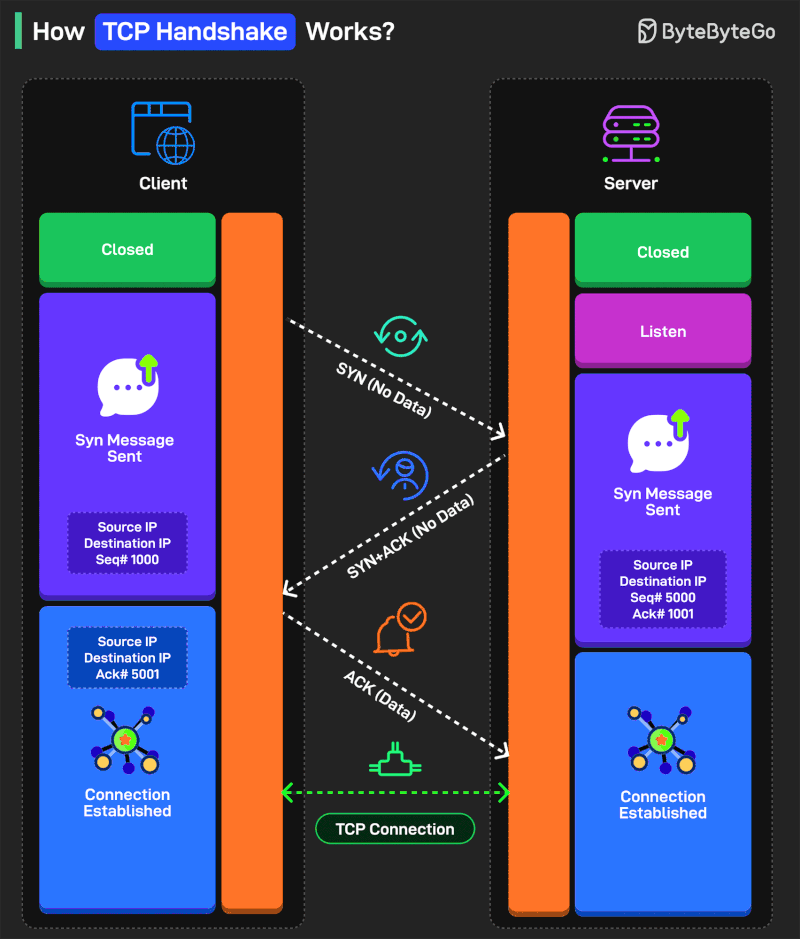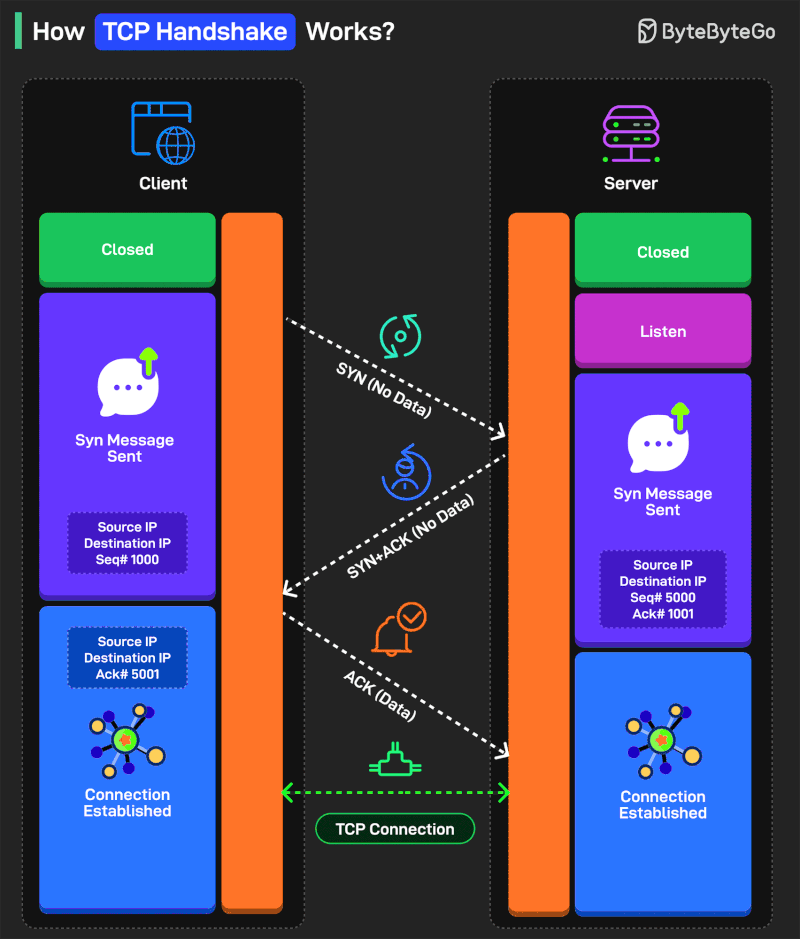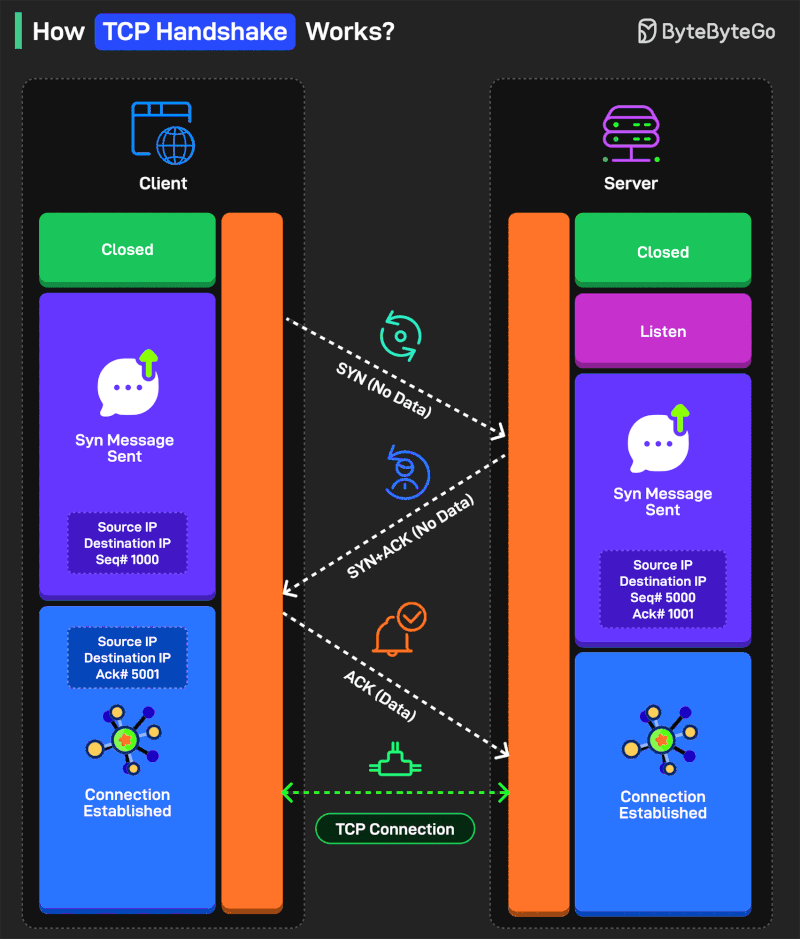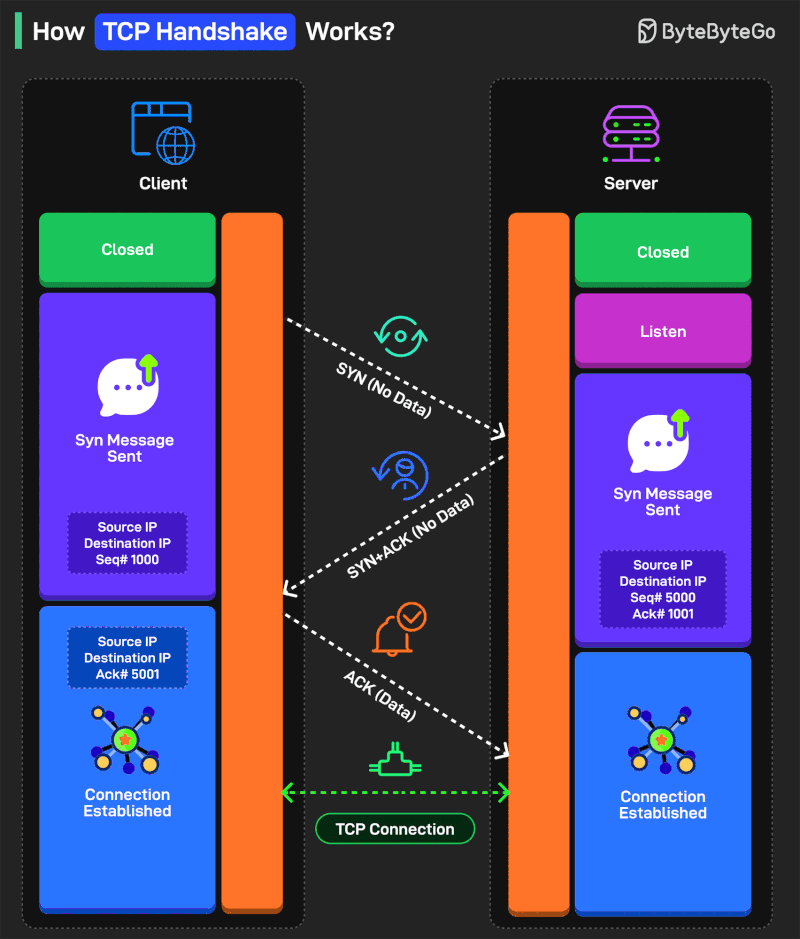
Handshake 프로세스에는 세 단계가 있습니다:
-
SYN (Synchronize) 한 쪽이 악수를 위해 손을 내미는 것으로 생각하면 됩니다. 프로세스는 클라이언트가 SYN 플래그와 함께 TCP 세그먼트를 서버에 전송하면서 시작됩니다. 또한 초기 시퀀스 번호(ISN)도 메시지와 함께 전송됩니다.
-
SYN-ACK 상대방이 악수에 동의하는 것과 같습니다. 서버가 SYN 세그먼트를 수신하고 TCP 세그먼트를 클라이언트에 전송하여 응답합니다. 세그먼트에 SYN 플래그와 ACK 플래그를 설정합니다. ACK 플래그는 ISN을 증가시켜 클라이언트의 SYN 세그먼트 수신을 확인하기 위한 것입니다.
-
ACK 두 당사자가 악수하는 단계입니다. 클라이언트가 SYN-ACK 세그먼트를 수신하고 ACK 플래그가 설정된 다른 TCP 세그먼트를 전송하여 서버의 응답을 확인합니다. 시퀀스 번호는 서버의 ISN을 증가시킨 값으로 설정됩니다.
고려할 만한 추가 사항:
-
SYN과 ACK는 통신 프로세스의 다양한 측면을 관리하는 데 사용되는 제어 플래그입니다.
-
시퀀스 번호(ISN)는 클라이언트와 서버가 메시지 순서를 추적하여 누락되는 것이 없도록 돕습니다.
Over to you: TCP Handshake 프로세스를 더 잘 이해하기 위해 추가할 내용이 있나요?
Related Articles
Thank you for reading.