EP178: Kubernetes Pod의 생명주기
이번 주 시스템 설계 리프레셔:
-
Kubernetes Pod의 생명주기
-
CI/CD Pipeline 설명
-
오픈소스 RAG Stack
-
가장 인기 있는 버전 관리 전략
-
Production-Ready Data Science 도서
-
Testing Pyramid
Kubernetes Pod의 생명주기
-
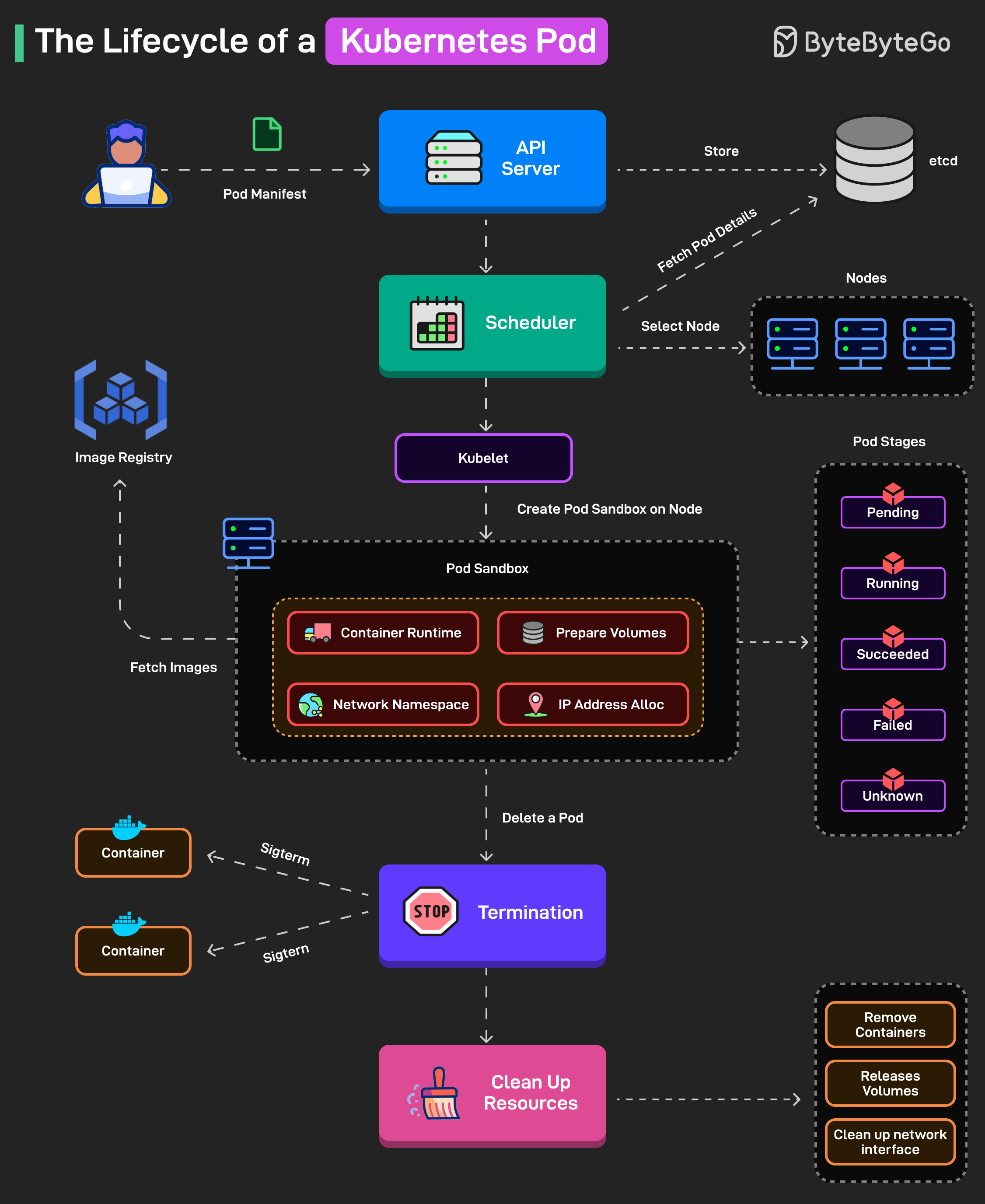
Pod manifest가 API server에 제출되고 etcd에 저장됩니다.
-
scheduler가 리소스, affinity 규칙을 기반으로 Pod를 위한 node를 선택하고, 해당 node에 Pod를 바인딩합니다.
-
kubelet이 network namespace를 생성하고, IP를 할당하며, volume을 마운트하고, 필요시 이미지를 pull하여 Pod를 준비합니다.
-
container들이 Waiting에서 Running 상태로 전환되며, kubelet이 liveness와 readiness를 위한 health probe를 모니터링합니다.
-
Kubernetes는 Pod의 고수준 phase를 Pending에서 Running, 그리고 Succeeded/Failed/Unknown으로 추적합니다.
-
종료 시, Kubernetes는 Pod 내 개별 container들에게 SIGTERM을 보내고 (필요시 SIGKILL도 전송합니다).
-
종료 후, 리소스가 정리되고 Pod 정보가 etcd에서 제거됩니다.
Over to you: Kubernetes Pod Lifecycle을 이해하기 위해 무엇을 더 추가하시겠습니까?
CI/CD Pipeline 설명
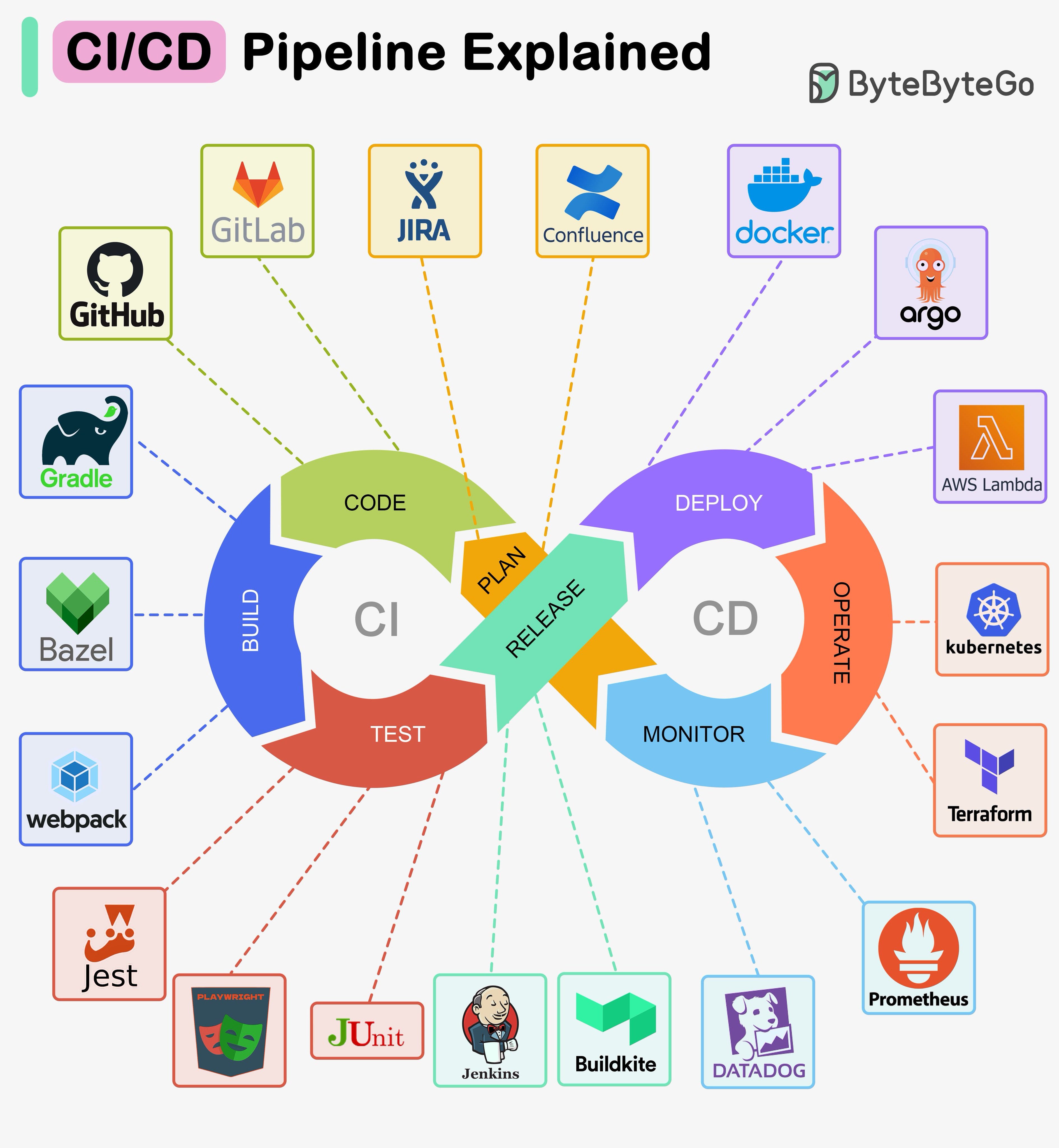
CI/CD pipeline은 소프트웨어를 빌드, 테스트, 배포하는 프로세스를 자동화하는 도구입니다.
코드 생성 및 수정, 테스트, 배포를 포함한 소프트웨어 개발 생명주기의 여러 단계를 하나의 통합된 워크플로우로 연결합니다.
아래 다이어그램은 일반적으로 사용되는 도구들을 보여줍니다.
오픈소스 RAG Stack

-
Frontend Frameworks: RAG 앱을 위한 프론트엔드 인터페이스를 구축하는 데 사용됩니다. NextJS, VueJS, SvelteKit, Streamlit 등의 도구가 도움이 됩니다.
-
LLM Frameworks: LLM pipeline, prompt, chain의 고수준 orchestration을 담당합니다. LangChain, LlamaIndex, Haystack, HuggingFace, Semantic Kernel 등의 도구가 포함됩니다.
-
LLMs: Large language model을 사용하여 최종 응답을 생성합니다. 오픈소스 옵션으로는 Llama, Mistral, Gemma, Phi-2, DeepSeek, Qwen 등이 있습니다.
-
Retrieval and Ranking: 관련 chunk를 검색하고 관련성에 따라 순위를 매깁니다. Meta FAISS, Haystack Retrievers, Weaviate Hybrid Search, ElasticSearch kNN, JinaAI Rerankers 등의 도구가 도움이 됩니다.
-
Vector Database: vector embedding에 대한 유사도 검색을 저장하고 가능하게 합니다. 일반적인 옵션으로는 Weaviate, Milvus, Postgres pgVector, Chroma, Pinecone이 있습니다.
-
Embedding Model: ML을 사용하여 텍스트/데이터를 vector 표현으로 변환합니다. 오픈소스 도구로는 HuggingFace Transformers, LLMWare, Nomic, Sentence Transformers, JinaAI, Cognita 등이 있습니다.
-
Ingest/Data Processing: 인덱싱 및 검색을 위해 원시 데이터를 추출, 정제, 준비합니다. Kubeflow, Apache Airflow, Apache NiFi, LangChain Document Loads, Haystack Pipelines, OpenSearch 등의 도구가 도움이 됩니다.
Over to you: 목록에 어떤 오픈소스 도구를 추가하시겠습니까?
가장 인기 있는 버전 관리 전략은 무엇인가요?
버전 관리는 개발자들이 소프트웨어 패키지, API, 운영체제 등의 릴리스 변경 사항을 명확하게 전달하는 데 도움이 됩니다.
-
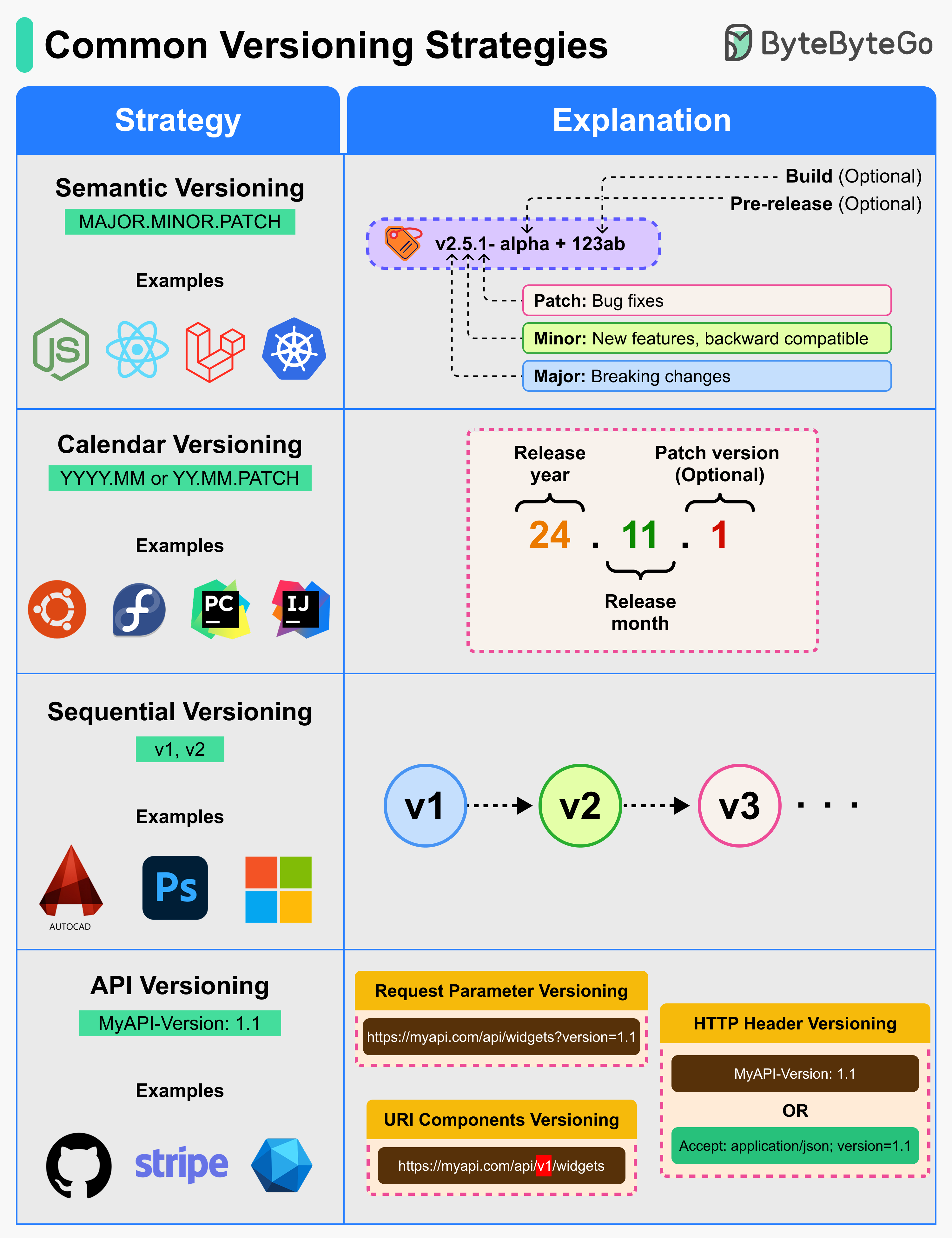
Semantic Versioning (SemVer): MAJOR.MINOR.PATCH 형식을 사용하여 릴리스의 변경 범위에 대한 의미를 전달하는 버전 관리 체계입니다.
-
Calendar Versioning (CalVer): 릴리스 날짜(연도와 월)를 버전 번호로 사용하여 릴리스가 언제 발생했는지를 나타내는 체계입니다.
-
Sequential Versioning: 호환성 세부 정보를 인코딩하지 않고 순차적으로 버전이 증가하는 단순한 번호 지정 방식입니다.
-
API Versioning: breaking change를 관리하고 분리하기 위해 API의 URL 경로에 버전을 포함하는 방법입니다.
여러분께 질문드립니다: 어떤 버전 관리 전략을 선호하시나요? 그 이유는 무엇인가요?
Production-Ready Data Science 도서
제 친구 Khuyen Tran이 Production-Ready Data Science라는 책을 썼습니다. 빠른 프로토타입과 견고한 솔루션 사이의 간극을 메워주는 책을 찾고 계신다면, 확인해 보세요.
이 책은 다음 기술들을 마스터하는 데 도움이 되는 실용적인 예제와 명확한 설명을 제공합니다:
-
지저분한 notebook을 정리되고 유지보수 가능한 코드로 변환하기
-
팀과 배포 환경 전반에서 재현 가능한 환경 만들기
-
모듈화되고, 재사용 가능하며, 테스트 가능한 Python 코드 작성하기
-
견고한 데이터 검증 및 에러 핸들링 구현하기
-
그 외 다양한 내용
책에서 논의된 모든 개념의 실용적인 구현이 담긴 GitHub 저장소는 여기에서 확인하세요.
Testing Pyramid
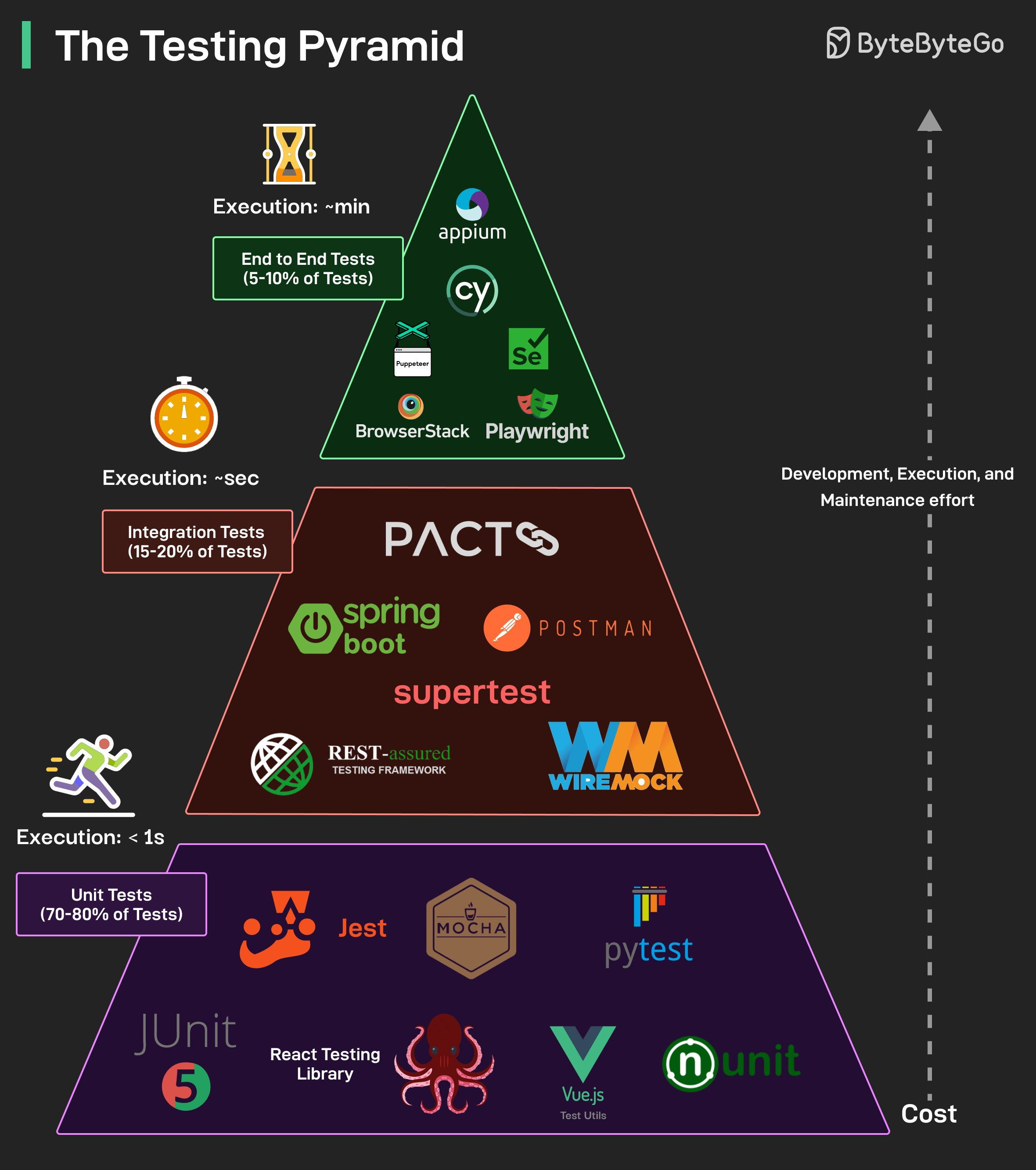
테스팅은 신뢰할 수 있는 소프트웨어의 근간입니다. Testing Pyramid는 테스트를 세 가지 핵심 레이어로 구조화하는 널리 인정받는 전략입니다:
-
Unit Tests: 피라미드의 기반입니다. Unit test는 빠르고, 격리되어 있으며, 작성 및 유지 비용이 낮습니다. 개별 함수, 메서드, 또는 컴포넌트를 테스트합니다.
-
Integration Tests: API, 데이터베이스, 외부 서비스 등 컴포넌트 간의 상호작용을 검증합니다. Unit test보다 느리고 더 많은 설정이 필요합니다.
-
E2E Tests: 전체 시스템에 걸쳐 처음부터 끝까지 실제 사용자 흐름을 시뮬레이션합니다. 작성 및 유지 비용이 높고 실행 속도가 느린 경향이 있습니다.
피라미드 위로 올라갈수록 테스트 개발, 실행, 유지보수 비용이 증가합니다.
Over to you: 테스팅 전략에서 어떤 레이어가 가장 가치 있다고 생각하시나요? 그 이유는 무엇인가요?
Related Articles
Thank you for reading.