EP179: 쿠버네티스 기초 설명
이번 주 시스템 디자인 복습 내용입니다:
- System Design: Design YouTube (유튜브 영상)
- 알아야 할 9가지 Docker Best Practices
- Kubernetes Explained
- N8N vs LangGraph
- 어디서 데이터를 캐싱할까?
- ByteByteGo 기술 면접 준비 키트
System Design: Design YouTube
알아야 할 9가지 Docker Best Practices

1. 공식 이미지를 사용하세요 보안, 신뢰성, 정기적인 업데이트를 보장합니다.
2. 특정 이미지 버전을 사용하세요
기본 latest 태그는 예측 불가능하며 예상치 못한 동작을 유발합니다.
3. Multi-Stage 빌드를 활용하세요 빌드 도구와 의존성을 제외하여 최종 이미지 크기를 줄입니다.
4. .dockerignore를 사용하세요 불필요한 파일을 제외하여 빌드 속도를 높이고 이미지 크기를 줄입니다.
5. 최소 권한 사용자를 사용하세요 컨테이너 권한을 제한하여 보안을 강화합니다.
6. 환경 변수를 사용하세요 다양한 환경에서의 유연성과 이식성을 높입니다.
7. 순서가 캐싱에 중요합니다 캐싱을 최적화하기 위해 변경이 적은 것부터 자주 변경되는 것 순으로 단계를 정렬하세요.
8. 이미지에 라벨을 붙이세요 조직화를 개선하고 이미지 관리에 도움이 됩니다.
9. 이미지를 스캔하세요 보안 취약점이 더 큰 문제가 되기 전에 발견하세요.
여러분 차례입니다: 이 목록에 어떤 Docker best practices를 추가하시겠습니까?
Kubernetes Explained
Kubernetes는 컨테이너 오케스트레이션의 사실상 표준입니다. 컨테이너화된 애플리케이션의 배포, 스케일링, 관리를 자동화합니다.
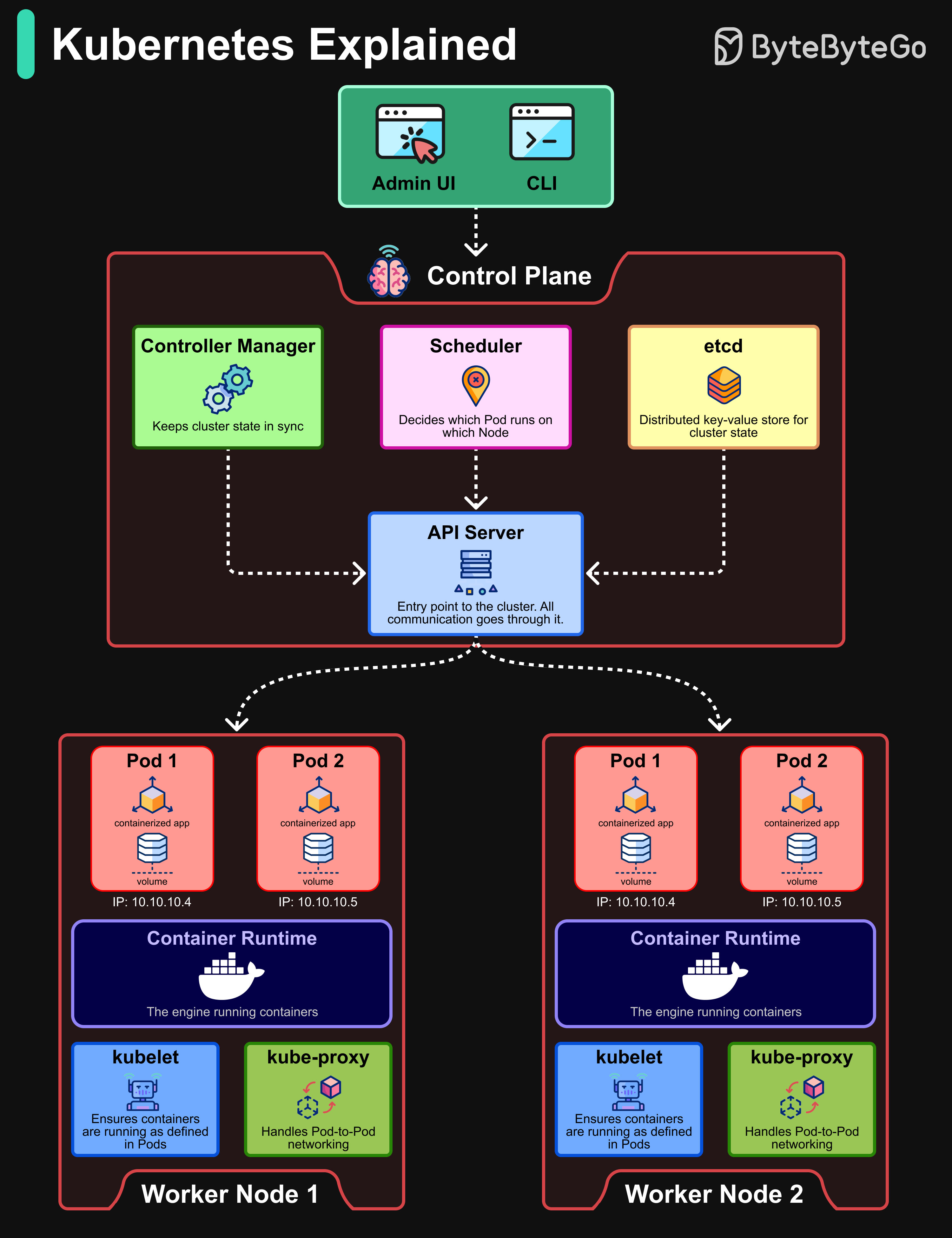
Control Plane:
- API Server: 사용자, control plane, worker node 간의 통신 허브 역할을 합니다.
- Scheduler: 어떤 Pod가 어떤 Node에서 실행될지 결정합니다.
- Controller Manager: 클러스터 상태를 동기화 상태로 유지합니다.
- etcd: 클러스터의 상태를 보관하는 분산 key-value 저장소입니다.
Worker Nodes:
- Pods: Kubernetes에서 가장 작은 배포 단위로, 하나 이상의 컨테이너를 나타냅니다.
- Container Runtime: 컨테이너를 실행하는 엔진입니다 (Docker나 containerd 같은).
- kubelet: Pod에 정의된 대로 컨테이너가 실행되도록 보장합니다.
- kube-proxy: Pod 간 네트워킹을 처리하고 통신을 보장합니다.
여러분 차례입니다: 프로덕션에서 Kubernetes를 운영할 때 가장 어려운 부분은 무엇인가요?
N8N vs LangGraph
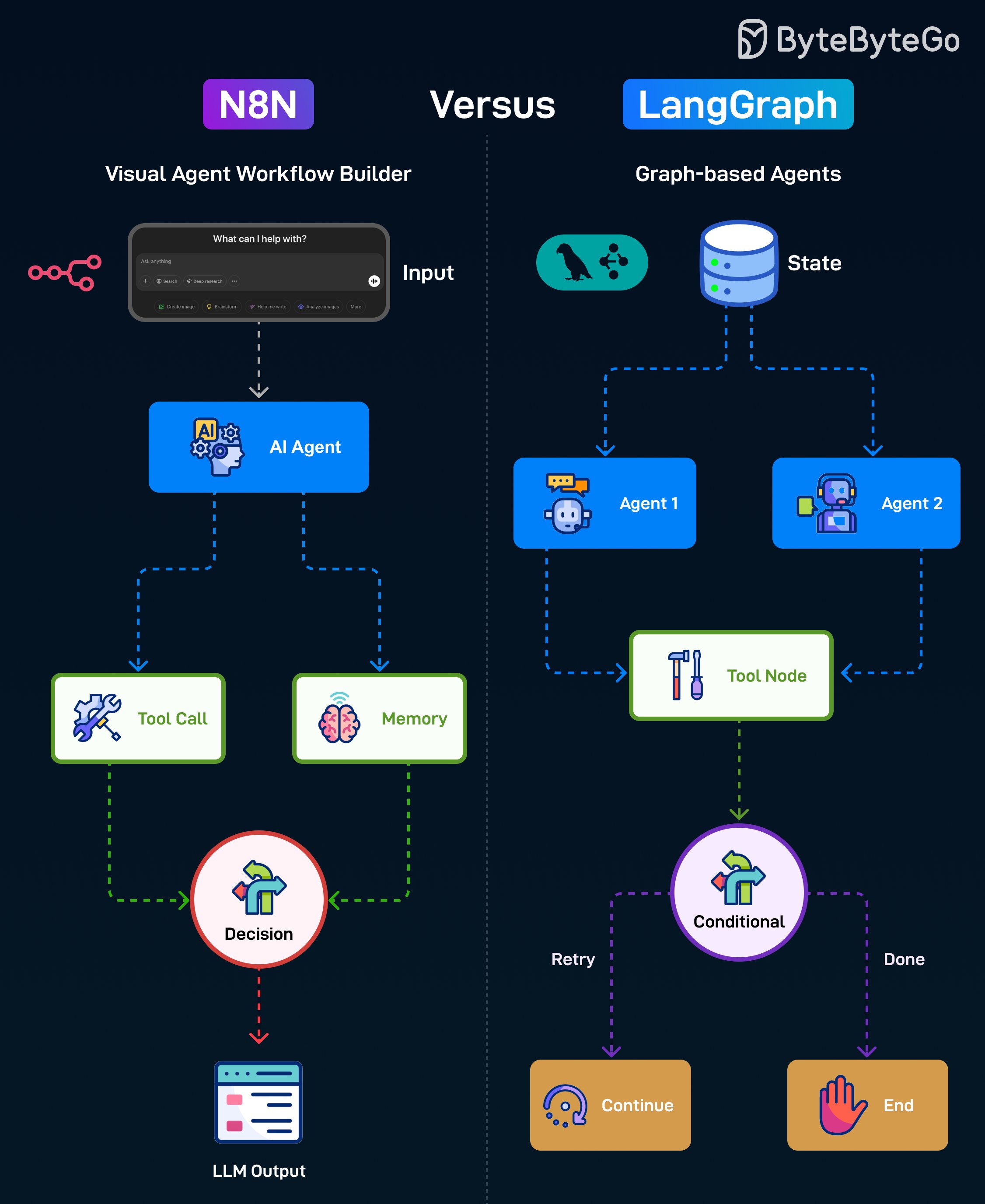
N8N
N8N은 다양한 서비스, API, AI 도구를 순차적으로 연결하여 워크플로우를 시각적으로 구축할 수 있게 해주는 오픈소스 자동화 도구입니다. 작동 방식은 다음과 같습니다:
- 사용자로부터 Input으로 시작합니다.
- 처리를 위해 AI Agent로 전달합니다.
- AI Agent는 Tool Call을 하거나 Memory에 접근할 수 있습니다.
- Decision 노드가 다음 액션을 선택하고 사용자를 위한 최종 LLM output을 생성합니다.
LangGraph
LangGraph는 분기, 루프, 멀티 에이전트 협업을 지원하는 유연한 그래프 구조를 사용하여 AI Agent 워크플로우를 구축하는 Python 프레임워크입니다. 작동 방식은 다음과 같습니다:
- 워크플로우 컨텍스트를 포함하는 공유 State로 시작합니다.
- 태스크를 다른 에이전트로 라우팅할 수 있습니다.
- 에이전트는 태스크를 수행하기 위해 Tool Node와 상호작용합니다.
- Conditional 노드가 재시도할지 프로세스를 완료로 표시할지 결정합니다.
여러분 차례입니다: N8N이나 LangGraph를 사용해 보신 적 있나요?
어디서 데이터를 캐싱할까?
데이터는 프론트엔드부터 백엔드까지 모든 곳에서 캐싱됩니다!
이 다이어그램은 일반적인 아키텍처에서 데이터를 어디서 캐싱하는지 보여줍니다.
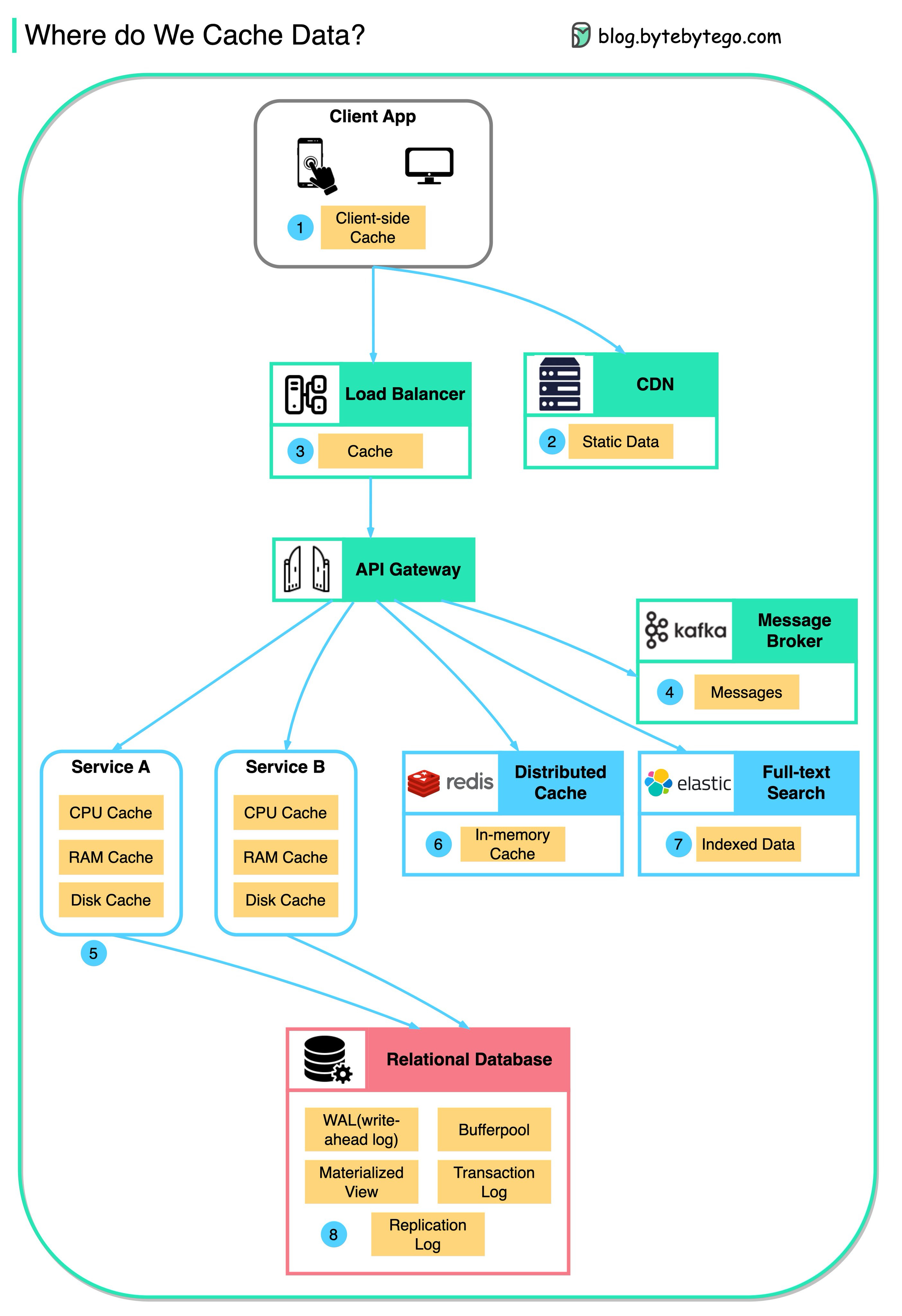
흐름을 따라 여러 레이어가 있습니다.
Client apps
HTTP 응답은 브라우저에 의해 캐싱될 수 있습니다. HTTP로 처음 데이터를 요청하면, HTTP 헤더에 만료 정책과 함께 반환됩니다. 다시 데이터를 요청할 때, 클라이언트 앱은 먼저 브라우저 캐시에서 데이터를 가져오려고 시도합니다.
CDN
CDN은 정적 웹 리소스를 캐싱합니다. 클라이언트는 가까운 CDN 노드에서 데이터를 가져올 수 있습니다.
Load Balancer
Load Balancer도 리소스를 캐싱할 수 있습니다.
Messaging infra
메시지 브로커는 먼저 메시지를 디스크에 저장하고, 그 후 컨슈머가 자신의 속도에 맞게 가져갑니다. 보존 정책에 따라 데이터는 일정 기간 동안 Kafka 클러스터에 캐싱됩니다.
Services
서비스 내에는 여러 레이어의 캐시가 있습니다. 데이터가 CPU 캐시에 없으면, 서비스는 메모리에서 데이터를 가져오려고 시도합니다. 때로는 서비스가 디스크에 데이터를 저장하는 2차 캐시를 가지고 있기도 합니다.
Distributed Cache
Redis와 같은 Distributed Cache는 여러 서비스를 위한 key-value 쌍을 메모리에 보관합니다. 데이터베이스보다 훨씬 나은 읽기/쓰기 성능을 제공합니다.
Full-text Search
때로는 문서 검색이나 로그 검색을 위해 Elastic Search와 같은 전문 검색을 사용해야 합니다. 데이터의 복사본이 검색 엔진에도 인덱싱됩니다.
Database
데이터베이스 내에서도 다양한 레벨의 캐시가 있습니다:
- WAL(Write-ahead Log): B tree 인덱스를 구축하기 전에 먼저 WAL에 데이터가 기록됩니다.
- Bufferpool: 쿼리 결과를 캐싱하기 위해 할당된 메모리 영역입니다.
- Materialized View: 더 나은 쿼리 성능을 위해 쿼리 결과를 미리 계산하여 데이터베이스 테이블에 저장합니다.
- Transaction log: 모든 트랜잭션과 데이터베이스 업데이트를 기록합니다.
- Replication Log: 데이터베이스 클러스터에서 복제 상태를 기록하는 데 사용됩니다.
여러분 차례입니다: 이렇게 많은 레벨에서 데이터가 캐싱되는데, 민감한 사용자 데이터가 시스템에서 완전히 삭제되었음을 어떻게 보장할 수 있을까요?
ByteByteGo 기술 면접 준비 키트
올인원 면접 준비를 출시합니다. 모든 책을 ByteByteGo 웹사이트에서 제공합니다.
포함 내용:
- System Design Interview
- Coding Interview Patterns
- Object-Oriented Design Interview
- How to Write a Good Resume
- Behavioral Interview (출시 예정)
- Machine Learning System Design Interview
- Generative AI System Design Interview
- Mobile System Design Interview
- 그 외 더 많은 콘텐츠 예정
Related Articles
Thank you for reading.