EP182: 쿠키 vs 세션
EP182: Cookies vs Sessions
이번 주 시스템 설계 복습:
-
FAANG System Design Interview: Design A Chat System (Youtube 영상)
-
Cookies vs Sessions
-
Access Control 명확하게 설명
-
Full Fine-Tuning vs LoRA vs RAG
-
Git Reset은 어떻게 동작하는가?
-
Apache Kafka 설명 (하이 레벨)
Cookies vs Sessions
모든 웹 애플리케이션은 사용자가 로그인한 후에도 해당 사용자를 기억하는 방법이 필요합니다. 이를 관리하는 방식에 따라 웹 애플리케이션의 성능, 확장성, 보안에 큰 차이가 발생합니다.
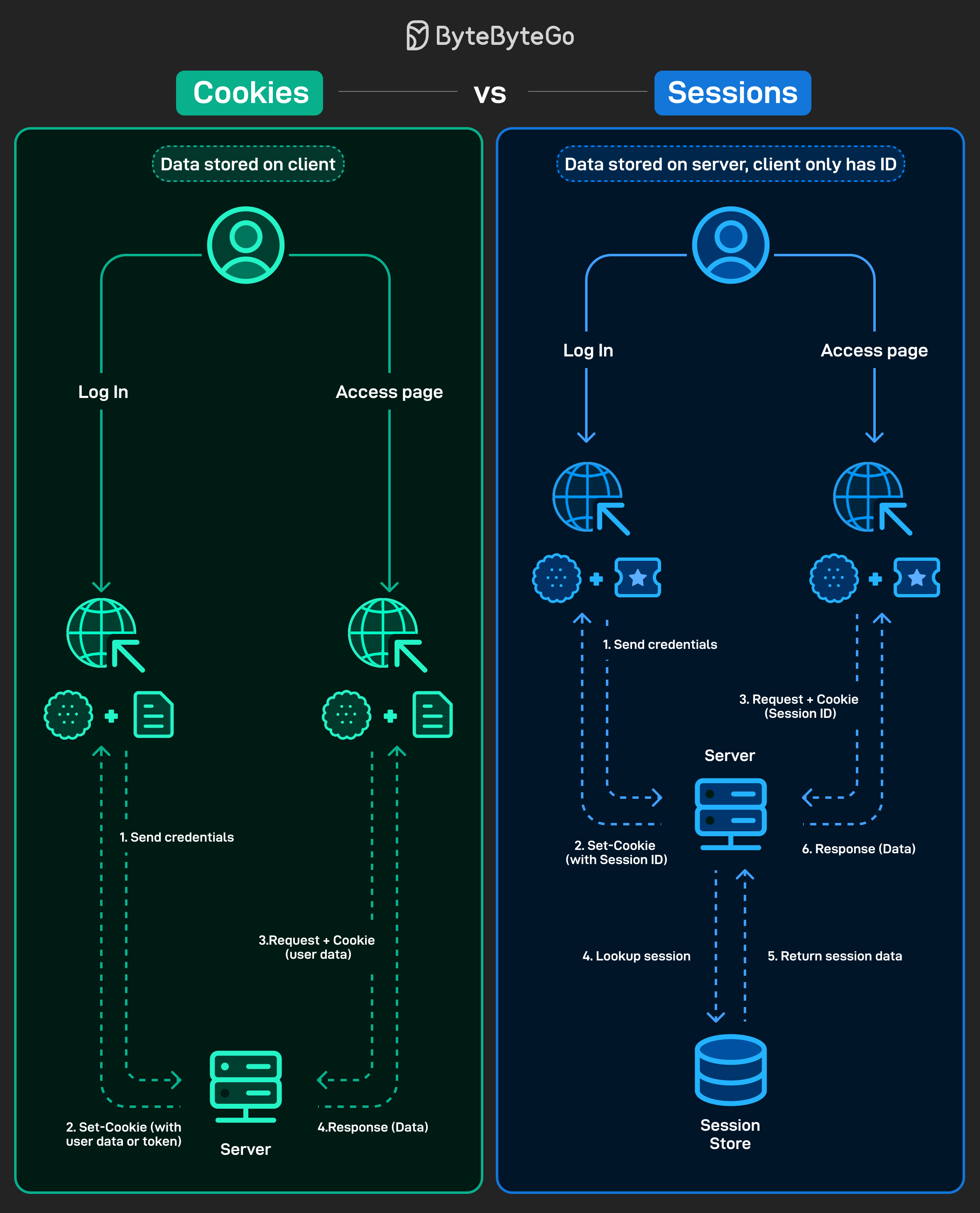
Cookies:
-
데이터를 클라이언트에 직접 저장합니다 (사용자 정보나 token 등).
-
매 요청마다 cookie가 서버로 전송됩니다.
-
구현이 간단하지만, 적절히 보안 처리하지 않으면 데이터가 노출될 수 있습니다.
Sessions:
-
데이터를 서버에 저장하고, 클라이언트는 Session ID만 cookie에 보관합니다.
-
매 요청마다 Session ID를 사용하며, 서버는 session store에서 데이터를 조회합니다.
-
더 안전하지만, 추가적인 서버 측 저장소와 관리가 필요합니다.
여러분에게 질문: cookie, session, 아니면 token 기반 인증 중 어떤 방식을 선호하시나요?
Access Control 명확하게 설명
Access control은 누가 들어올 수 있고 누가 차단되는지를 결정합니다 — 하지만 그 규칙은 모델마다 다릅니다.
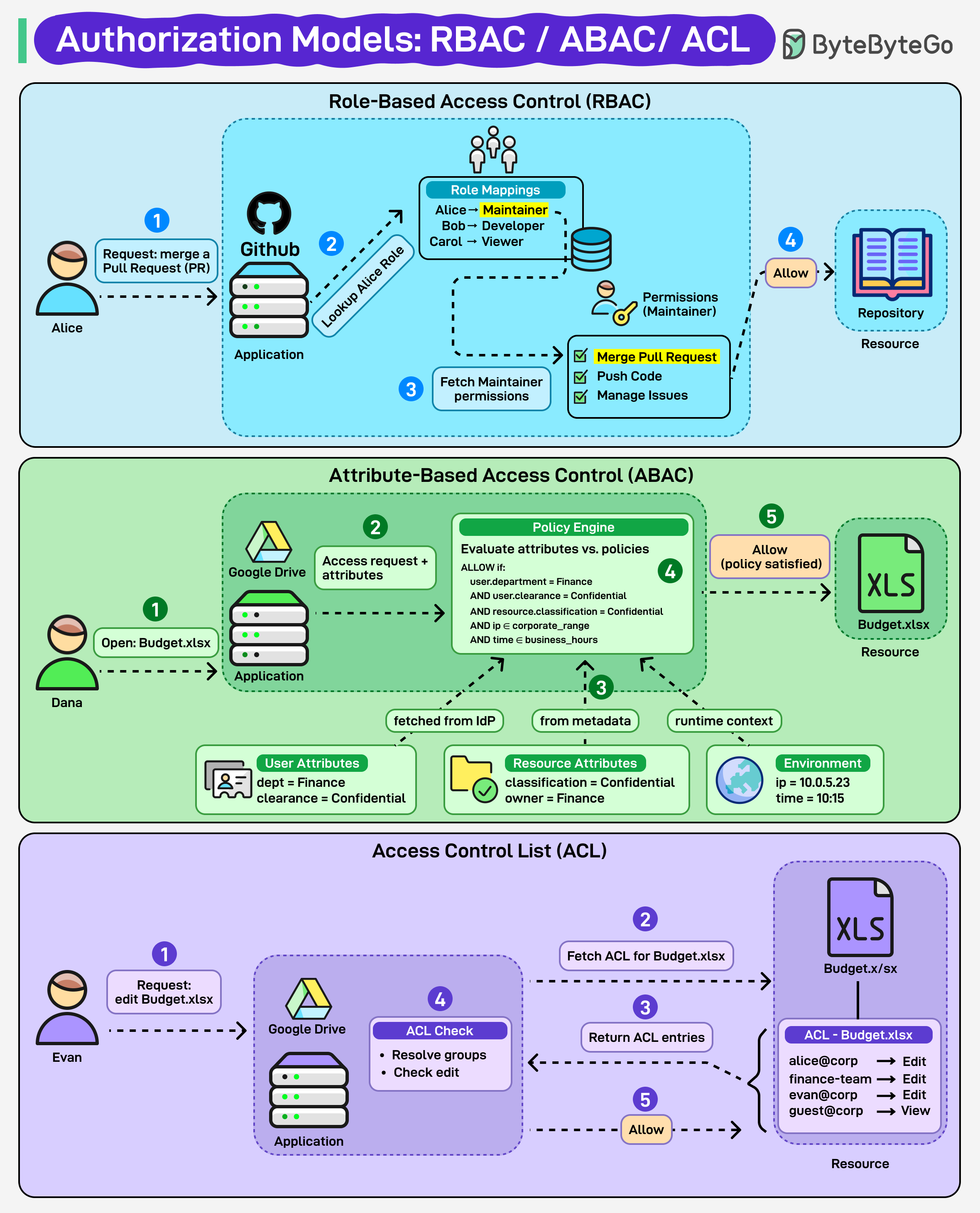
Role-Based Access Control (RBAC): 역할에 기반한 접근 제어입니다 (예: Maintainer, Viewer). 단순하고 확장성이 좋습니다.
Attribute-Based Access Control (ABAC): 속성에 기반한 접근 제어입니다 (사용자, 리소스, 환경). 유연하지만 복잡합니다.
Access Control List (ACL): 각 사용자나 그룹에 대한 명시적 권한입니다. 직관적이지만 규모가 커지면 관리하기 어렵습니다.
-
RBAC = 역할
-
ABAC = 속성
-
ACL = 명시적 권한
여러분에게 질문: 한 모델에서 다른 모델로 전환해 본 경험이 있으신가요? 어떤 이유로 변경하셨나요?
Full Fine-Tuning vs LoRA vs RAG
이 세 가지는 사전 학습된 대규모 언어 모델을 새로운 작업이나 지식에 적응시키는 서로 다른 방법입니다.
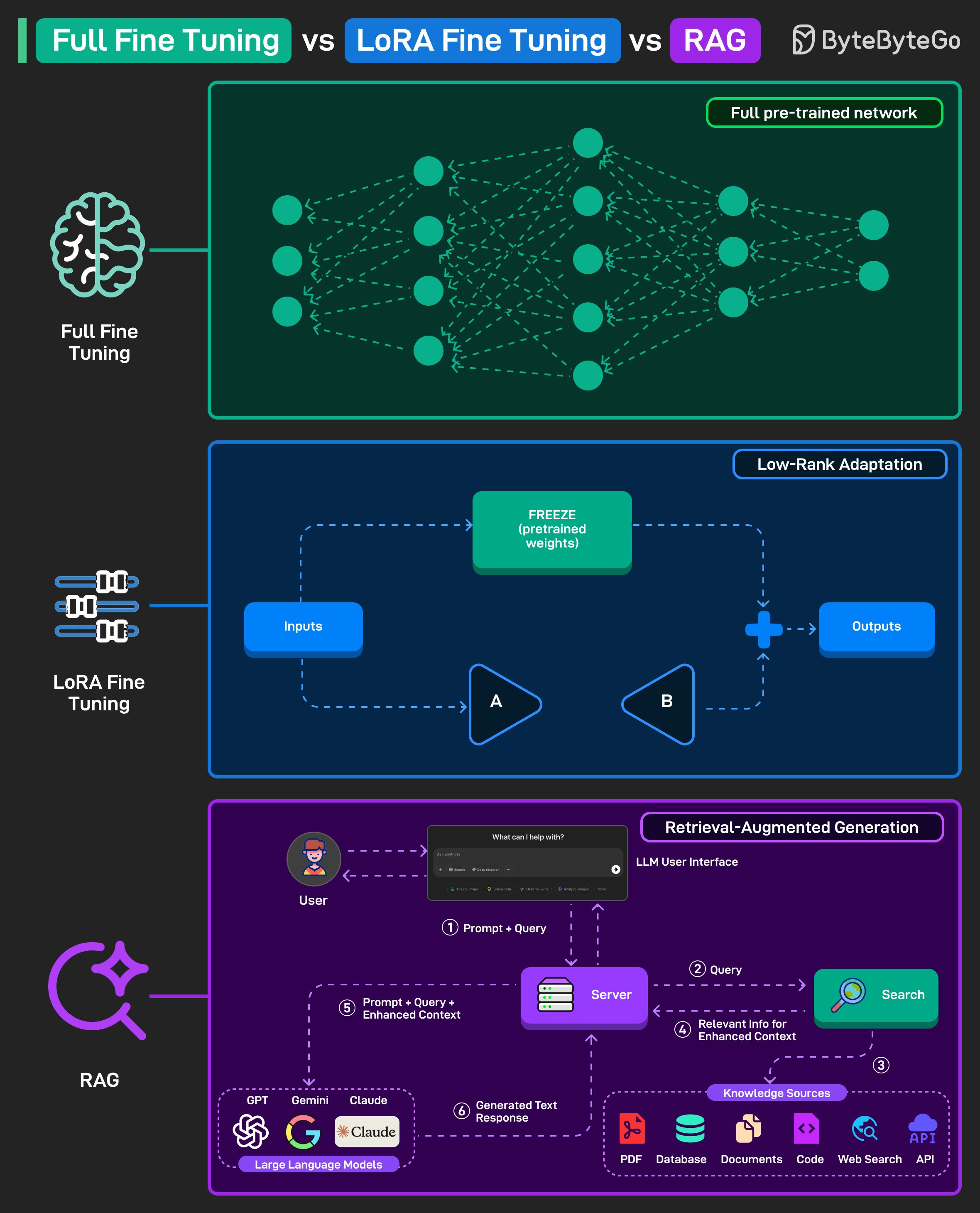
Full Fine-Tuning 전체 사전 학습 모델을 새로운 데이터로 재훈련합니다. 네트워크의 모든 가중치가 업데이트되므로 높은 정확도를 얻을 수 있지만, 더 많은 컴퓨팅 파워와 저장 공간이 필요합니다.
LoRA Fine-Tuning LoRA는 Low-Rank Adaptation의 약자입니다. 전체 모델을 변경하는 대신, 메인 가중치는 고정(frozen)하고 작은 추가 레이어만 훈련합니다. Full fine-tuning보다 훨씬 빠르고 저렴하면서도 새로운 작업에 모델을 적응시킬 수 있습니다.
RAG RAG는 Retrieval-Augmented Generation의 약자입니다. 모델을 재훈련하지 않습니다. 대신 필요할 때마다 외부 소스(데이터베이스, 웹, 문서 등)에서 정보를 검색합니다. 쿼리가 관련 컨텍스트로 강화된 후 모델에 전달되어, 무거운 재훈련 없이도 더 정확하고 최신 정보를 제공합니다.
여러분에게 질문: 다른 fine-tuning 기법을 본 적이 있으신가요?
Git Reset은 어떻게 동작하는가?
Git Reset은 현재 git 브랜치(HEAD)를 다른 commit으로 이동시키고, index와 working directory를 해당 commit과 일치하도록 만들 수 있습니다.
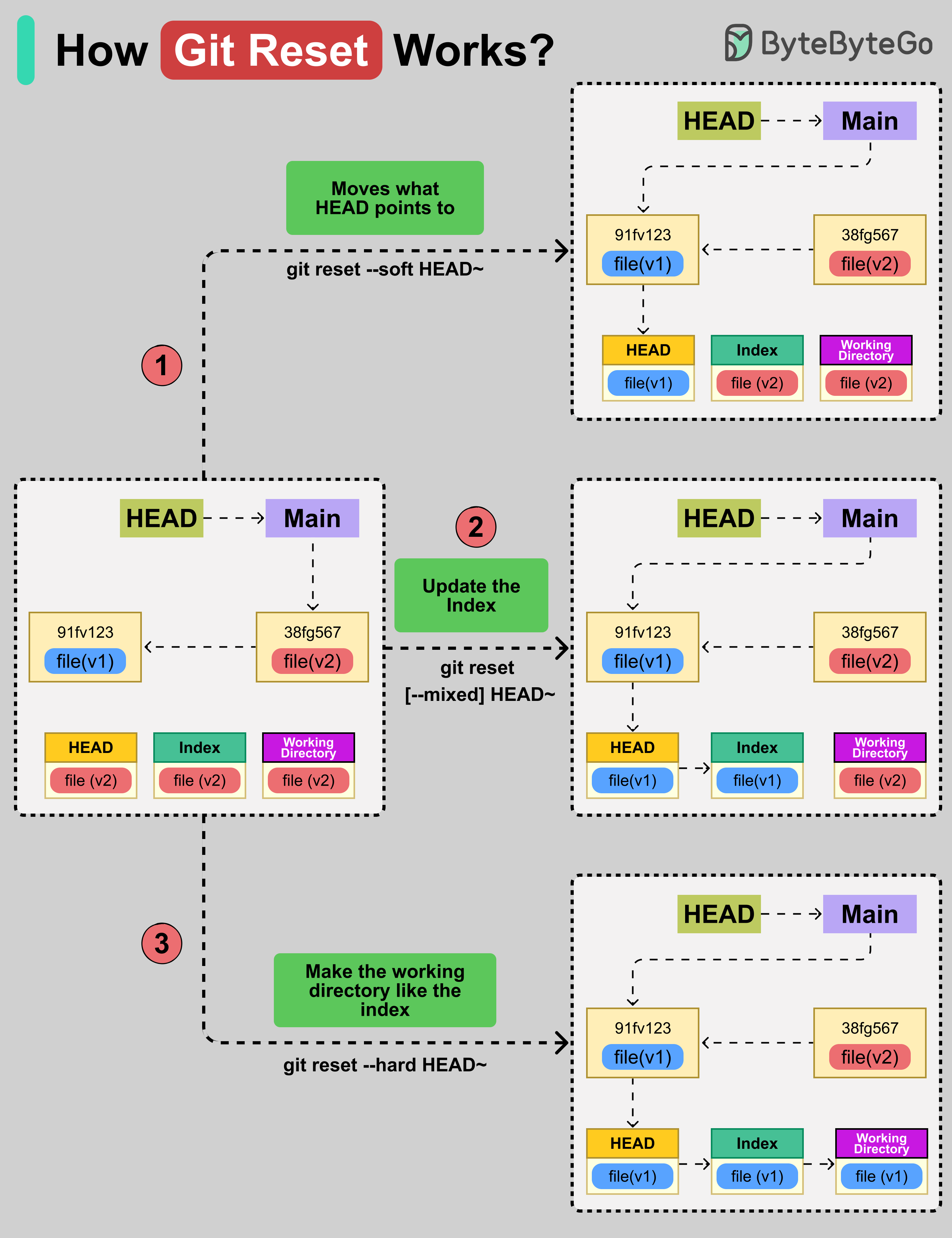
'git reset' 명령어에는 세 가지 옵션이 있습니다:
- HEAD 이동 (--soft)
HEAD가 가리키는 위치를 이동합니다. 하지만 index와 working 파일은 그대로 유지됩니다. 예를 들어, 'git reset --soft HEAD~' 명령어는 포인터를 한 commit 뒤로 이동시킵니다.
- Index 업데이트 (--mixed)
기본 옵션입니다. HEAD가 이제 가리키는 스냅샷의 내용으로 index를 업데이트하지만, working 파일은 그대로 둡니다.
- Working Directory 업데이트 (--hard)
이 옵션은 HEAD를 이동하고, index를 리셋하며, working directory를 해당 commit과 일치시킵니다. 'git reset --hard HEAD~' 명령어는 모든 것(포인터, index, 파일)을 이전 commit으로 설정합니다.
여러분에게 질문: 프로젝트에서 Git Reset을 사용해 본 적이 있으신가요?
Apache Kafka 설명 (하이 레벨)
Netflix에서 Uber, LinkedIn에 이르기까지 Apache Kafka는 그들의 실시간 데이터 인프라의 중추입니다. 낮은 latency와 높은 신뢰성으로 대규모 데이터 스트림을 처리하도록 설계된 분산 이벤트 스트리밍 플랫폼입니다.
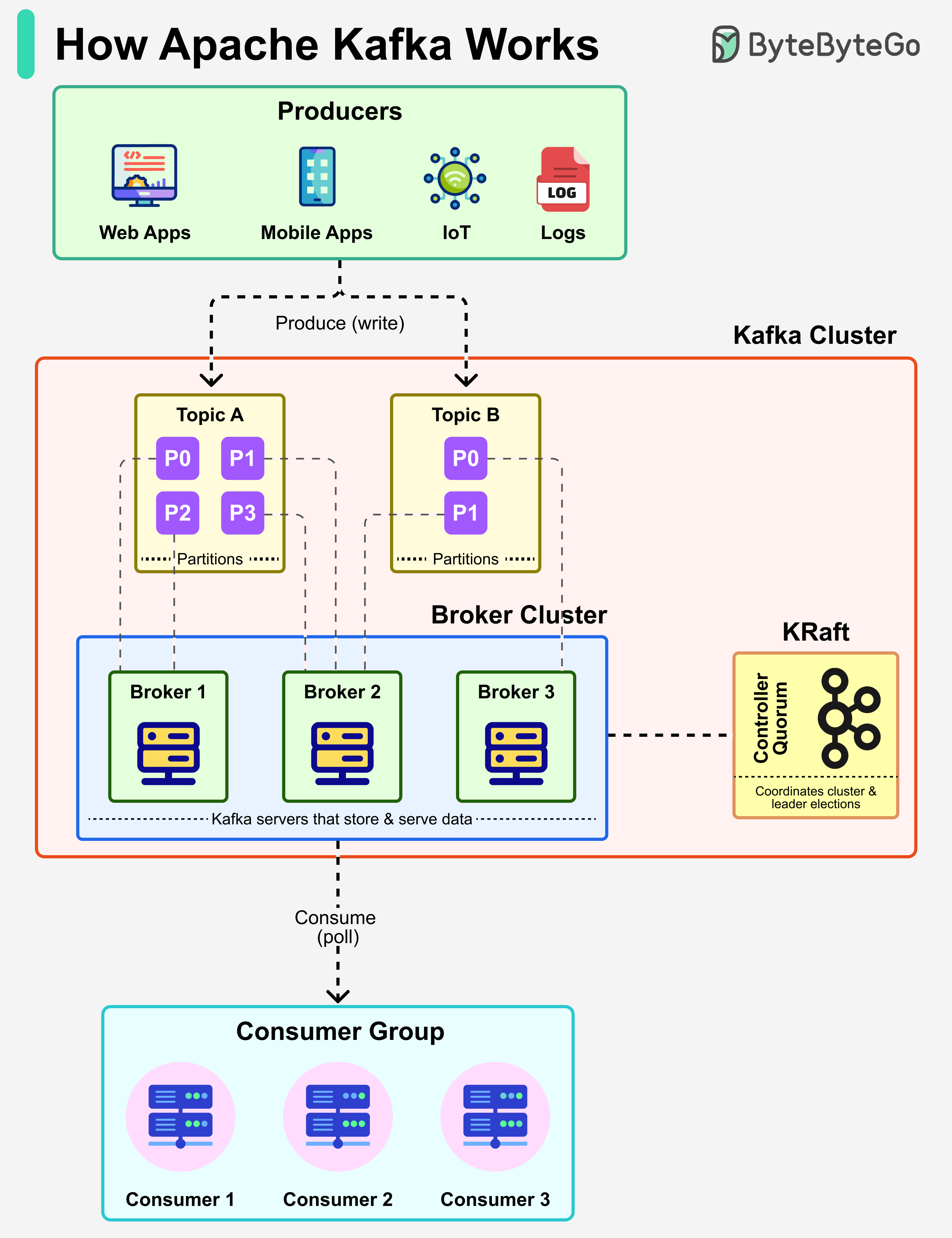
-
Producers: Kafka topic에 메시지를 발행하는 애플리케이션입니다 (웹, 모바일, IoT, 로그 등).
-
Topics & Partitions: 메시지는 topic으로 구성되며, 확장성과 병렬 처리를 위해 partition으로 분할됩니다.
-
Broker Cluster: Kafka broker는 partition된 데이터를 저장하고 제공합니다. 여러 broker가 클러스터를 구성하여 신뢰성과 fault tolerance를 보장합니다.
-
KRaft (Controller Quorum): 클러스터 메타데이터와 리더 선출을 조정하여 클러스터의 일관성을 유지합니다.
-
Consumer Groups: topic을 구독하고 메시지를 소비하는 애플리케이션입니다.
여러분에게 질문: 실시간 파이프라인과 이벤트 기반 마이크로서비스 중 어디에 더 많이 사용하시나요?
Related Articles
Thank you for reading.