EP186: Latency vs. Throughput
이번 주 System Design 리프레셔:
- Latency vs. Throughput
- 반드시 알아야 할 System Design 핵심 개념 20가지
- 느린 API를 어떻게 디버깅할 것인가?
- LLM이 세상을 바라보는 방식
- RAG vs Fine-tuning: 어떤 것을 선택해야 할까?
Latency vs. Throughput
앱의 Bandwidth가 충분해 보이는데도 왜 느리게 느껴지는지 궁금했던 적이 있으신가요? Latency와 Throughput은 성능에 대해 완전히 다른 두 가지 이야기를 설명해 줍니다.
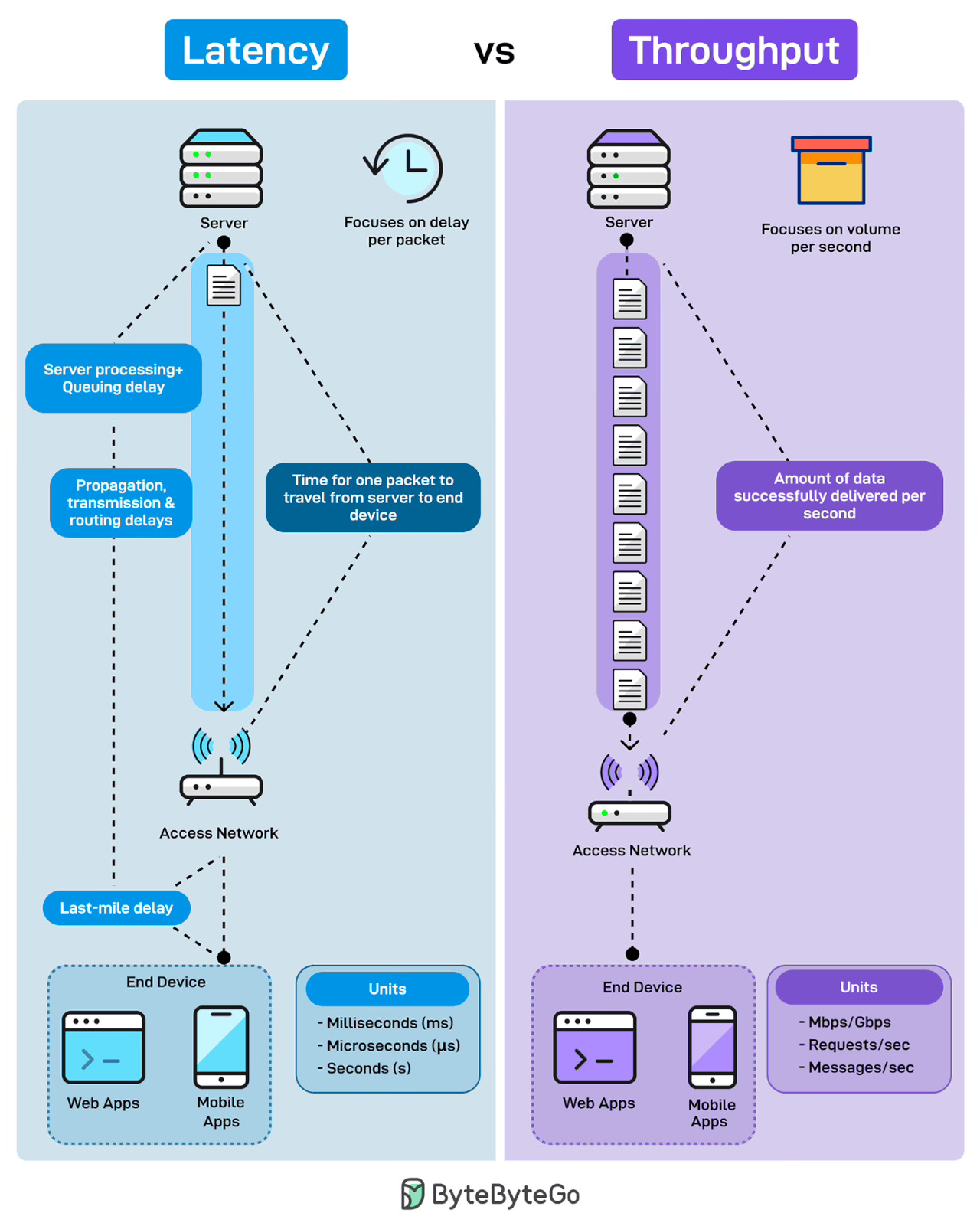
Latency는 패킷당 지연 시간을 측정합니다. 사용자가 버튼을 클릭했을 때 느끼는 것이 바로 이것입니다. 응답성이죠. 하나의 Request가 서버에서 사용자의 기기까지 도달하는 데 걸리는 시간입니다. 여기에는 서버 처리 시간, 큐잉 지연, 네트워크를 통한 전파 지연, 전송 지연, 그리고 사용자 기기까지의 Last-mile 연결이 모두 포함됩니다.
Throughput은 초당 처리량을 측정합니다. 주어진 시간 내에 얼마나 많은 데이터가 성공적으로 전달되는지를 나타냅니다. 각 패킷이 얼마나 빠르게 이동하는지가 아니라, 얼마나 많은 패킷이 파이프를 통해 흐르는지가 핵심입니다. Throughput은 용량입니다. 높은 Throughput은 시스템이 부하를 처리하면서도 병목 없이 운영된다는 것을 의미합니다.
여러분에게 묻습니다: 시스템이 언제 문제가 발생할지 실제로 예측할 수 있는 방식으로 이러한 지표들을 어떻게 측정하고 계신가요?
반드시 알아야 할 System Design 핵심 개념 20가지

- Load Balancing: 안정성과 가용성을 위해 트래픽을 여러 서버에 분산합니다.
- Caching: 더 빠른 접근을 위해 자주 액세스하는 데이터를 메모리에 저장합니다.
- Database Sharding: 대규모 데이터 증가를 처리하기 위해 데이터베이스를 분할합니다.
- Replication: 가용성과 장애 허용을 위해 데이터를 복제본에 복사합니다.
- CAP Theorem: Consistency, Availability, Partition Tolerance 간의 Trade-off입니다.
- Consistent Hashing: 동적인 서버 환경에서 부하를 균등하게 분산합니다.
- Message Queues: 비동기 이벤트 기반 아키텍처를 사용하여 서비스들을 분리합니다.
- Rate Limiting: 시스템 과부하를 방지하기 위해 요청 빈도를 제어합니다.
- API Gateway: API 요청을 라우팅하기 위한 중앙 진입점입니다.
- Microservices: 시스템을 독립적이고 느슨하게 결합된 서비스들로 분리합니다.
- Service Discovery: 분산 시스템에서 서비스를 동적으로 찾습니다.
- CDN: 속도를 위해 Edge 서버에서 콘텐츠를 제공합니다.
- Database Indexing: 중요한 필드에 인덱스를 생성하여 쿼리 속도를 높입니다.
- Data Partitioning: 확장성과 성능을 위해 데이터를 여러 노드에 분할합니다.
- Eventual Consistency: 분산 데이터베이스에서 시간이 지남에 따라 일관성을 보장합니다.
- WebSockets: 실시간 업데이트를 위한 양방향 통신을 가능하게 합니다.
- Scalability: 머신을 업그레이드하거나 추가하여 용량을 증가시킵니다.
- Fault Tolerance: 하드웨어/소프트웨어 장애 시에도 시스템 가용성을 보장합니다.
- Monitoring: 시스템 상태를 파악하기 위해 메트릭과 로그를 추적합니다.
- Authentication & Authorization: 사용자 접근을 제어하고 신원을 안전하게 확인합니다.
여러분에게 묻습니다: 이 목록에 추가하고 싶은 다른 System Design 개념이 있으신가요?
느린 API를 어떻게 디버깅할 것인가?
API가 느립니다. 사용자들이 불만을 제기하고 있습니다. 그런데 어디서부터 살펴봐야 할지 감이 안 잡힙니다. 여기 API를 느리게 만드는 원인을 추적하는 체계적인 접근 방법이 있습니다.
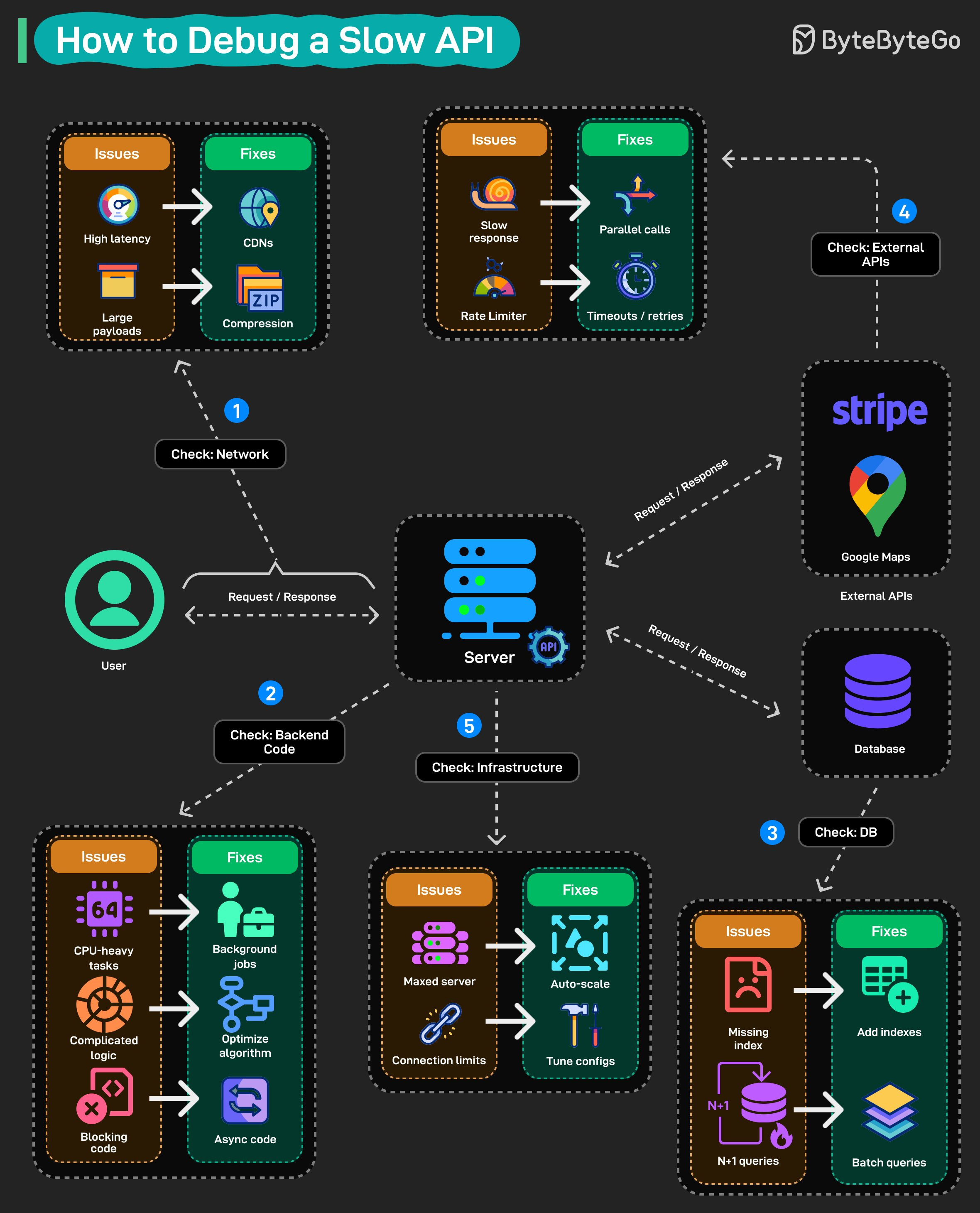
네트워크부터 시작하세요: Latency가 높나요? 정적 자산 앞에 CDN을 배치하세요. Payload가 크나요? Response를 압축하세요. 코드를 건드리지 않고도 얻을 수 있는 빠른 성과들입니다.
다음으로 Backend 코드를 확인하세요: 대부분의 성능 저하가 여기에 숨어 있습니다. CPU 집약적인 작업은 백그라운드에서 실행해야 합니다. 단순화가 필요한 복잡한 비즈니스 로직이 있을 수 있습니다. Async여야 하는데 Blocking 동기 호출로 되어 있는 경우도 있습니다. 프로파일링하고, Hot Path를 찾아내고, 수정하세요.
데이터베이스를 확인하세요: 누락된 인덱스가 전형적인 원인입니다. 또한 N+1 쿼리를 주의하세요. 한 번의 배치 쿼리로 충분한 상황에서 데이터베이스를 수백 번 호출하고 있을 수 있습니다.
외부 API를 잊지 마세요: Stripe 호출이든, Google Maps 요청이든, 이것들은 여러분의 통제 밖에 있습니다. 가능한 곳에서는 병렬 호출을 수행하세요. 하나의 느린 Third-party가 전체 Response를 망치지 않도록 공격적인 Timeout과 Retry를 설정하세요.
마지막으로 인프라를 확인하세요: 최대 부하에 도달한 서버는 Auto-scaling이 필요합니다. Connection Pool 한도는 튜닝이 필요합니다. 때로는 문제가 코드에 있는 게 아닙니다. 100개의 요청용으로 구축된 리소스로 10,000개의 요청을 처리하려고 하는 것일 수 있습니다.
핵심은 체계적으로 접근하는 것입니다. 솔루션을 무작정 시도하지 마세요. 먼저 측정하고, 실제 병목 지점을 파악한 다음, 수정하세요.
여러분에게 묻습니다: 지금까지 추적해낸 가장 이상한 성능 문제는 무엇이었나요?
LLM이 세상을 바라보는 방식
ChatGPT나 Claude에 "Hello world"를 입력하면, 모델은 여러분이 지금 이 글을 읽는 것처럼 그 글자와 공백을 처리하는 게 아닙니다. 대부분의 사람들이 생각하지 않는 과정을 통해 모든 것을 숫자로 변환하고 있습니다.
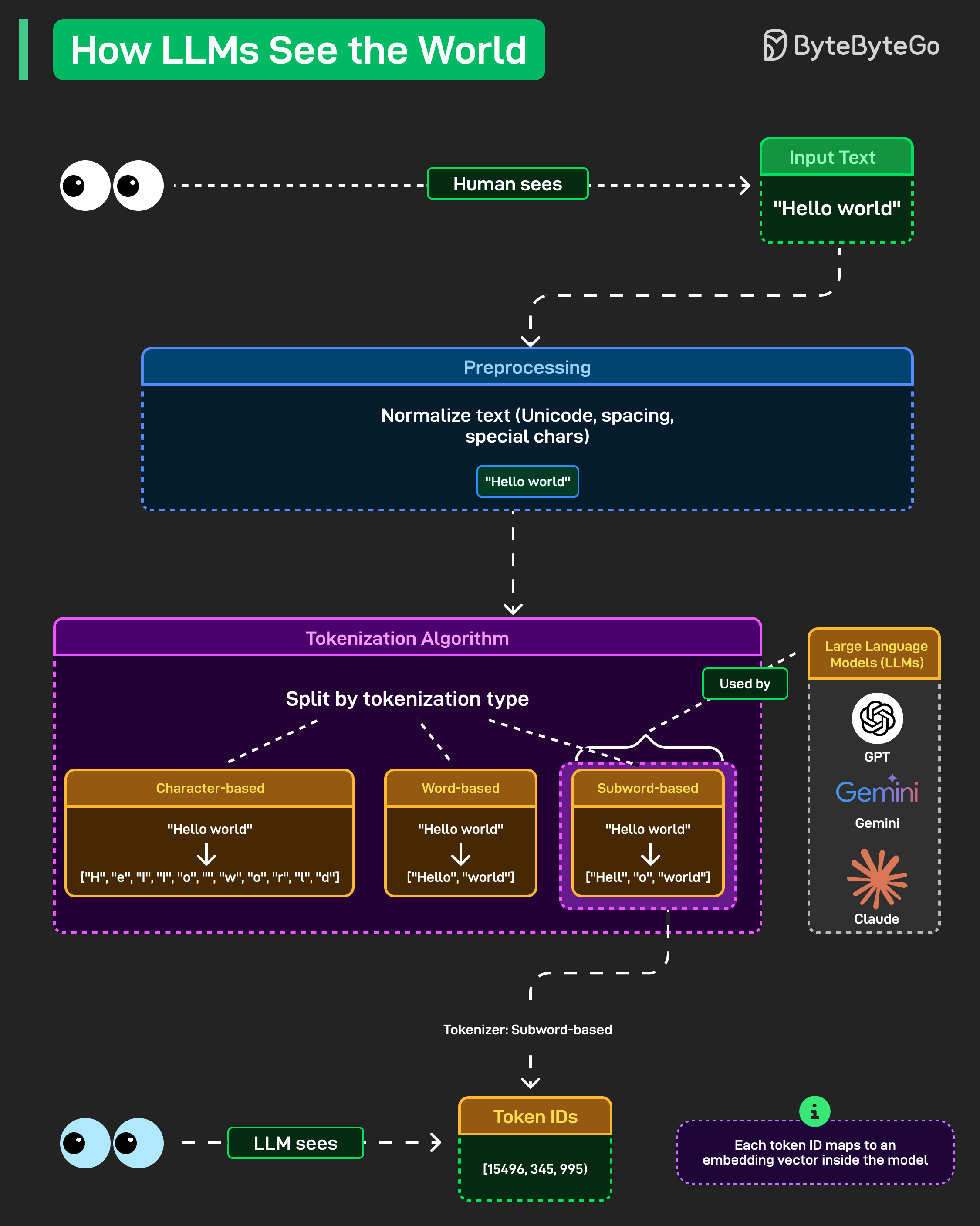
Preprocessing이 먼저 수행됩니다. 텍스트가 정규화됩니다. Unicode 문자, 공백 관련 특이사항, 특수 기호들이 모두 정리되고 표준화됩니다. "Hello world"는 모델이 실제로 작업할 수 있는 일관된 형식이 됩니다.
그다음 Tokenization이 진행됩니다. 여기서 흥미로워집니다. 모델은 텍스트를 Token으로 분할하는데, 여러 가지 접근 방식이 있습니다.
-
Character 기반 Tokenization은 모든 것을 개별 문자로 분해합니다. "Hello world"는 ["H", "e", "l", "l", "o", " ", "w", "o", "r", "l", "d"]가 됩니다. 단순하지만 비효율적입니다.
-
Word 기반은 전체 단어로 분할합니다. ["Hello", "world"]. 더 깔끔하지만 희귀 단어에서 어려움을 겪고 방대한 어휘를 생성합니다.
-
Subword 기반이 현대 LLM이 실제로 사용하는 방식입니다. GPT, Gemini, Claude 모두 이것에 의존합니다. "Hello world"는 ["Hell", "o", "world"]와 같은 형태가 됩니다. 효율성과 유연성의 균형을 맞추며, 희귀 단어를 알려진 Subword 조각으로 분해하여 처리합니다.
마지막 단계는 Token ID입니다. 이러한 Subword들이 [15496, 345, 995]와 같은 숫자로 매핑됩니다. 각 Token ID는 모델 내부의 Embedding Vector에 해당합니다. 그것이 Neural Network가 실제로 처리하는 대상입니다.
여러분에게 묻습니다: 왜 일부 모델은 자연어보다 코드를 더 잘 처리할까요? Tokenizer 때문일까요?
RAG vs Fine-tuning: 어떤 것을 선택해야 할까?
Large Language Models(LLM)을 새로운 작업에 적응시킬 때, 두 가지 인기 있는 접근 방식이 있습니다: Retrieval-Augmented Generation(RAG)과 Fine-tuning입니다. 둘 다 모델을 더 유용하게 만든다는 같은 문제를 해결하지만, 매우 다른 방식으로 접근합니다.
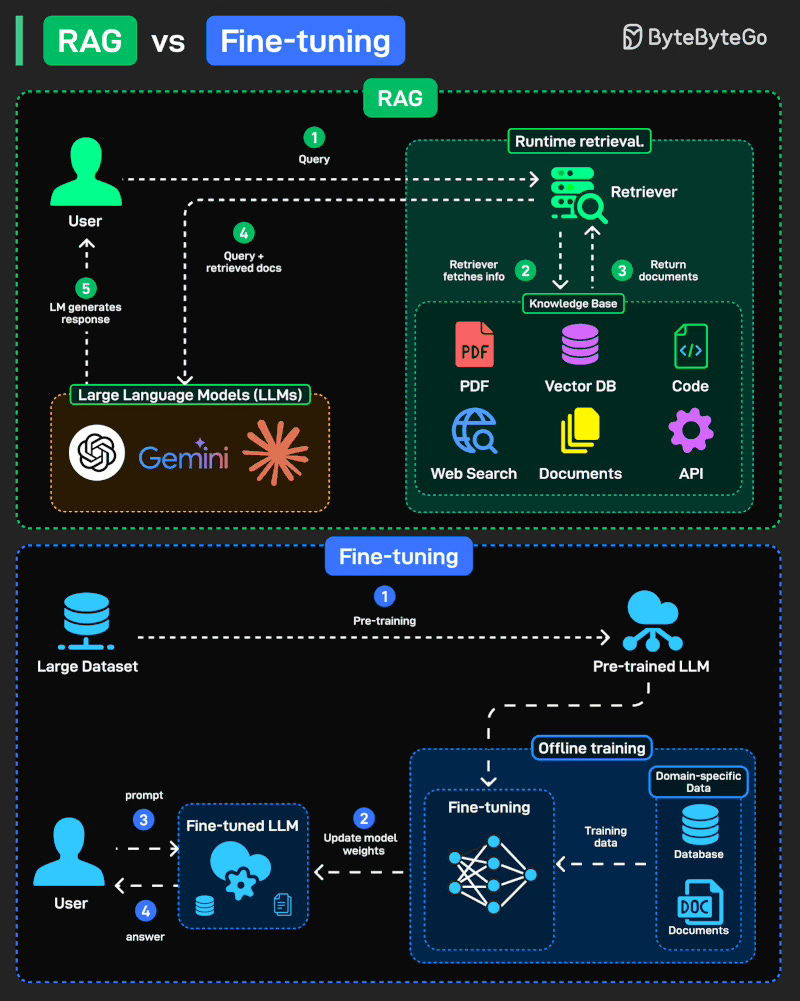
RAG (Retrieval-Augmented Generation): Runtime에 외부 소스(문서, DB, API)에서 지식을 가져옵니다. 유연하고, 항상 최신 상태입니다.
Fine-tuning: 도메인 특화 데이터로 모델 가중치를 업데이트하는 오프라인 학습입니다. 모델을 해당 분야의 전문가로 만듭니다.
여러분에게 묻습니다: 여러분의 도메인에서는 최신 지식(RAG)이 더 가치 있나요, 아니면 내재화된 전문성(Fine-tuning)이 더 가치 있나요?
Related Articles
Thank you for reading.