EP187: DeepSeek-OCR이 왜 큰 인기를 끌고 있나요?
이번 주 시스템 설계 복습:
- 우리가 매일 사용하는 10가지 핵심 자료구조
- 🚀 새로운 출시: AI 엔지니어 되기 | 실습으로 배우기 | 2기!
- 모든 엔지니어가 알아야 할 IP 주소 치트시트
- TCP와 UDP에서 실행되는 프로토콜
- DeepSeek-OCR이 왜 그렇게 대단한가?
우리가 매일 사용하는 10가지 핵심 자료구조
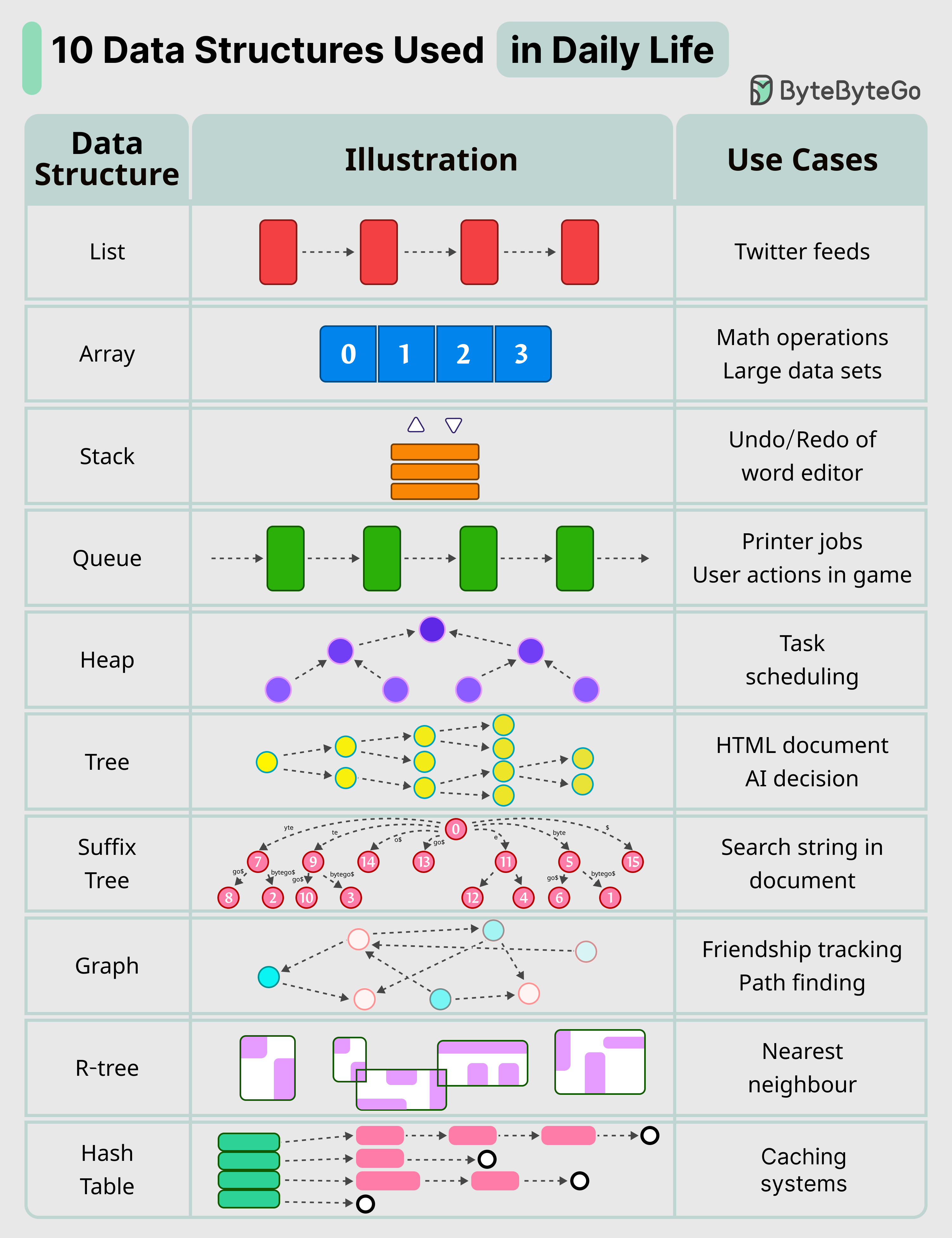
- List: Twitter 피드를 유지하는 데 사용됩니다
- Stack: 워드 에디터의 실행 취소/다시 실행 기능을 지원합니다
- Queue: 프린터 작업을 관리하거나, 게임 내 사용자 액션을 전송합니다
- Hash Table: 캐싱 시스템에 활용됩니다
- Array: 수학 연산에 사용됩니다
- Heap: 작업 스케줄링에 활용됩니다
- Tree: HTML 문서를 유지하거나, AI 의사결정에 사용됩니다
- Suffix Tree: 문서 내 문자열 검색에 활용됩니다
- Graph: 친구 관계 추적이나 경로 탐색에 사용됩니다
- R-Tree: 최근접 이웃 찾기에 활용됩니다
- Vertex Buffer: GPU로 렌더링 데이터를 전송하는 데 사용됩니다
여러분에게 질문: 우리가 놓친 추가적인 자료구조는 무엇이 있을까요?
🚀 새로운 출시: AI 엔지니어 되기 | 실습으로 배우기 | 2기!
첫 번째 기수의 놀라운 성공(거의 500명이 참여) 이후, AI 엔지니어 되기 2기의 출시를 알리게 되어 기쁩니다!

이것은 AI 프레임워크와 도구에 관한 또 하나의 강좌가 아닙니다. 우리의 목표는 엔지니어들이 AI 엔지니어로서 성장하는 데 필요한 기초와 end-to-end 스킬셋을 구축하도록 돕는 것입니다.
이번 기수가 특별한 이유는 다음과 같습니다:
- 실습으로 배우기: 동영상만 보는 것이 아니라, 실제 AI 애플리케이션을 직접 구축합니다.
- 체계적이고 시스템적인 학습 경로: 기초부터 고급 주제까지 단계별로 안내하는 세심하게 설계된 커리큘럼을 따릅니다.
- 라이브 피드백과 멘토십: 강사와 동료들로부터 직접 피드백을 받습니다.
- 커뮤니티 중심: 혼자 배우기는 어렵습니다. 커뮤니티와 함께 배우면 쉽습니다!
우리는 단순한 이론이나 수동적인 학습이 아닌, 스킬 구축에 집중합니다. 모든 참가자가 AI 시스템 구축을 위한 탄탄한 기초를 갖추고 떠나는 것이 우리의 목표입니다. 1기를 놓쳤다면, 지금이 2기에 합류할 기회입니다.
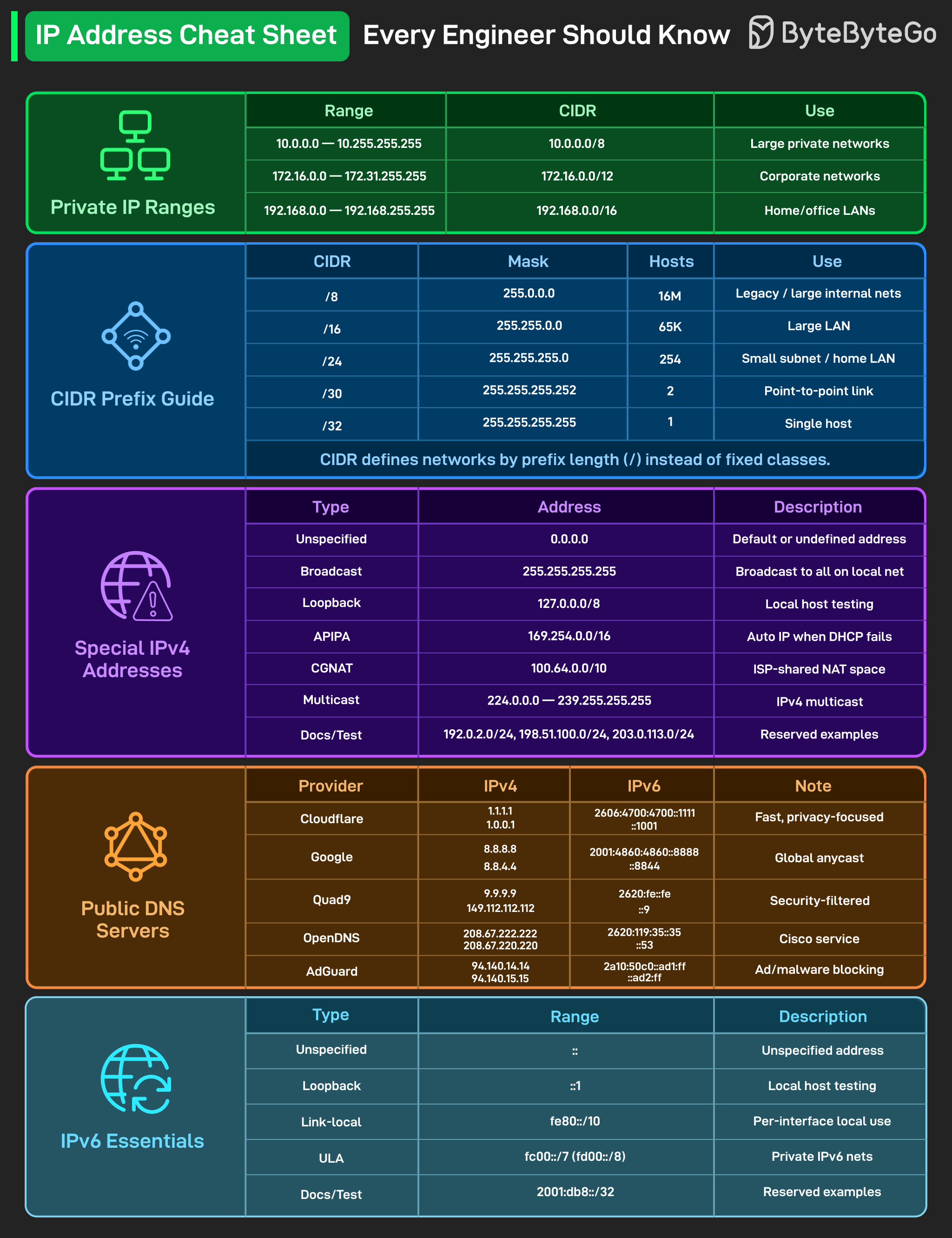
모든 엔지니어가 알아야 할 IP 주소 치트시트
TCP와 UDP에서 실행되는 프로토콜
인터넷을 통해 전송되는 모든 메시지에는 두 가지 통신 계층이 있습니다. 하나는 데이터를 운반하는 계층(transport)이고, 다른 하나는 데이터의 의미를 정의하는 계층(application)입니다. TCP와 UDP는 transport 계층에 위치하지만, 완전히 다른 목적을 수행합니다.
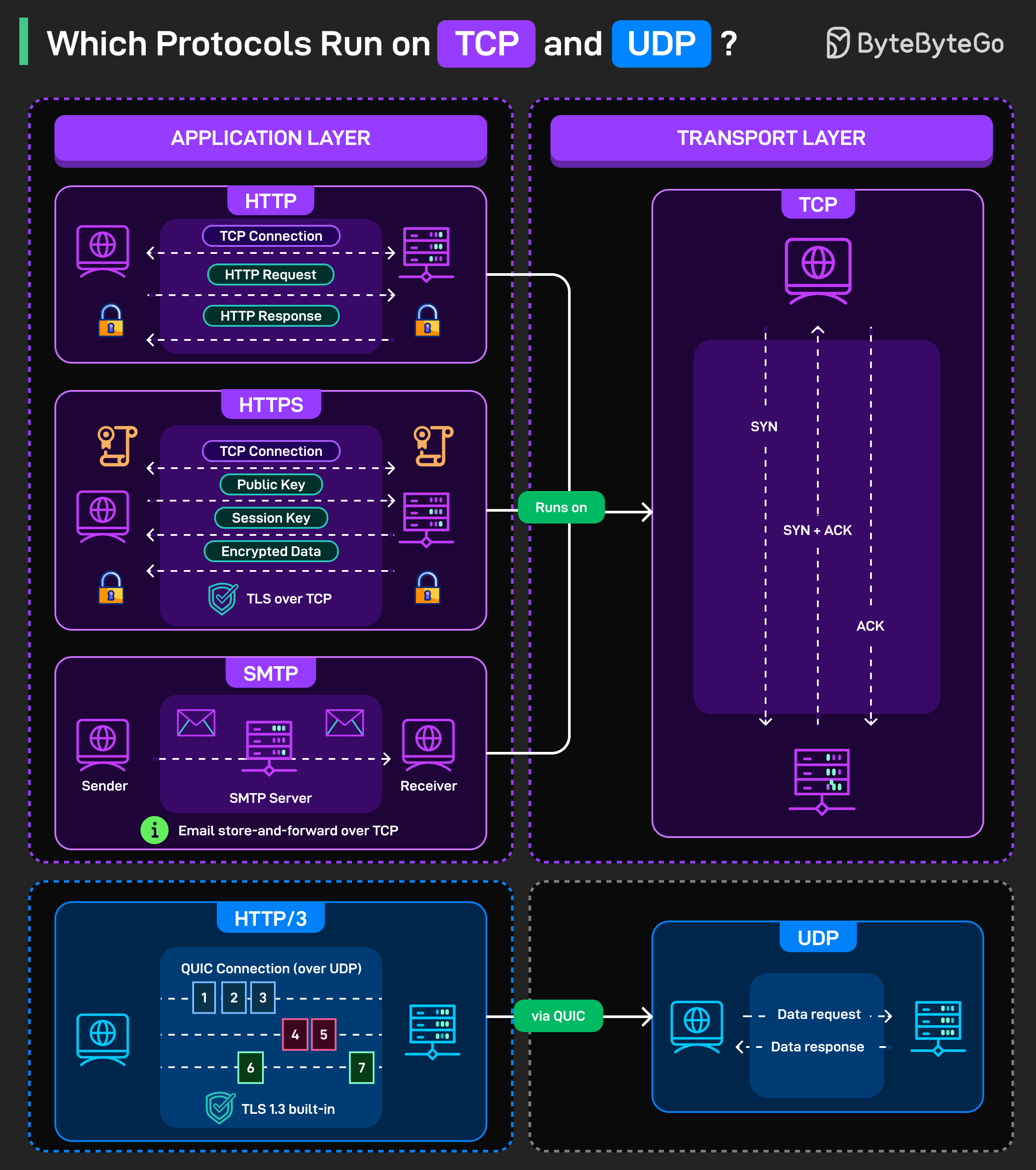
TCP는 connection-oriented입니다. 전송을 보장하고, 순서를 유지하며, 패킷이 손실되면 재전송을 처리합니다.
- HTTP는 TCP 위에서 실행됩니다. 브라우저는 TCP 연결을 열고, HTTP request를 보내고, HTTP response를 기다린 다음, 연결을 닫습니다(또는 후속 요청을 위해 연결을 유지합니다). 여러분이 로드한 모든 웹 페이지는 이 패턴을 사용했습니다.
- HTTPS는 TCP 위에 TLS를 추가합니다. 먼저 TCP 연결이 이루어집니다. 그 다음 public key 교환, session key 협상이 포함된 TLS handshake가 진행되고, 마지막으로 암호화된 데이터 전송이 이루어집니다.
- SMTP는 이메일을 위해 TCP를 사용합니다. 메시지는 발신자에서 SMTP 서버를 거쳐 수신자에게 TCP 연결을 통해 흐릅니다. 이메일은 전송 중 데이터 손실을 감당할 수 없으므로, TCP의 신뢰성이 필수적입니다.
UDP는 connectionless입니다. handshake가 없습니다. 전송 보장도 없습니다. 순서 보존도 없습니다. 그냥 데이터 요청과 응답을 네트워크로 발사하고 도착하길 바랍니다. 혼란스러워 보이지만, 빠릅니다.
- HTTP/3은 UDP를 사용하는 QUIC 위에서 실행됩니다. QUIC이 UDP 내부에서 TCP의 신뢰성 기능을 재구현하되 더 나은 성능으로 구현한다는 것을 알기 전까지는 이상하게 보입니다. 하나의 연결에서 여러 스트림이 가능합니다. 내장된 TLS 1.3이 있습니다. 더 빠른 연결 수립이 가능합니다. 다이어그램의 번호가 매겨진 스트림은 서로를 차단하지 않는 병렬 데이터 흐름을 보여줍니다.
여러분에게 질문: transport 계층 성능을 분석하기 위해 어떤 도구를 사용하시나요?
DeepSeek-OCR이 왜 그렇게 대단한가?
기존 LLM들은 고정된 수의 token만 처리할 수 있는 context window의 한계와 입력이 길어질수록 빠르게 증가하는 attention 비용 때문에 긴 입력에서 어려움을 겪습니다.
DeepSeek-OCR은 새로운 접근 방식을 취합니다.
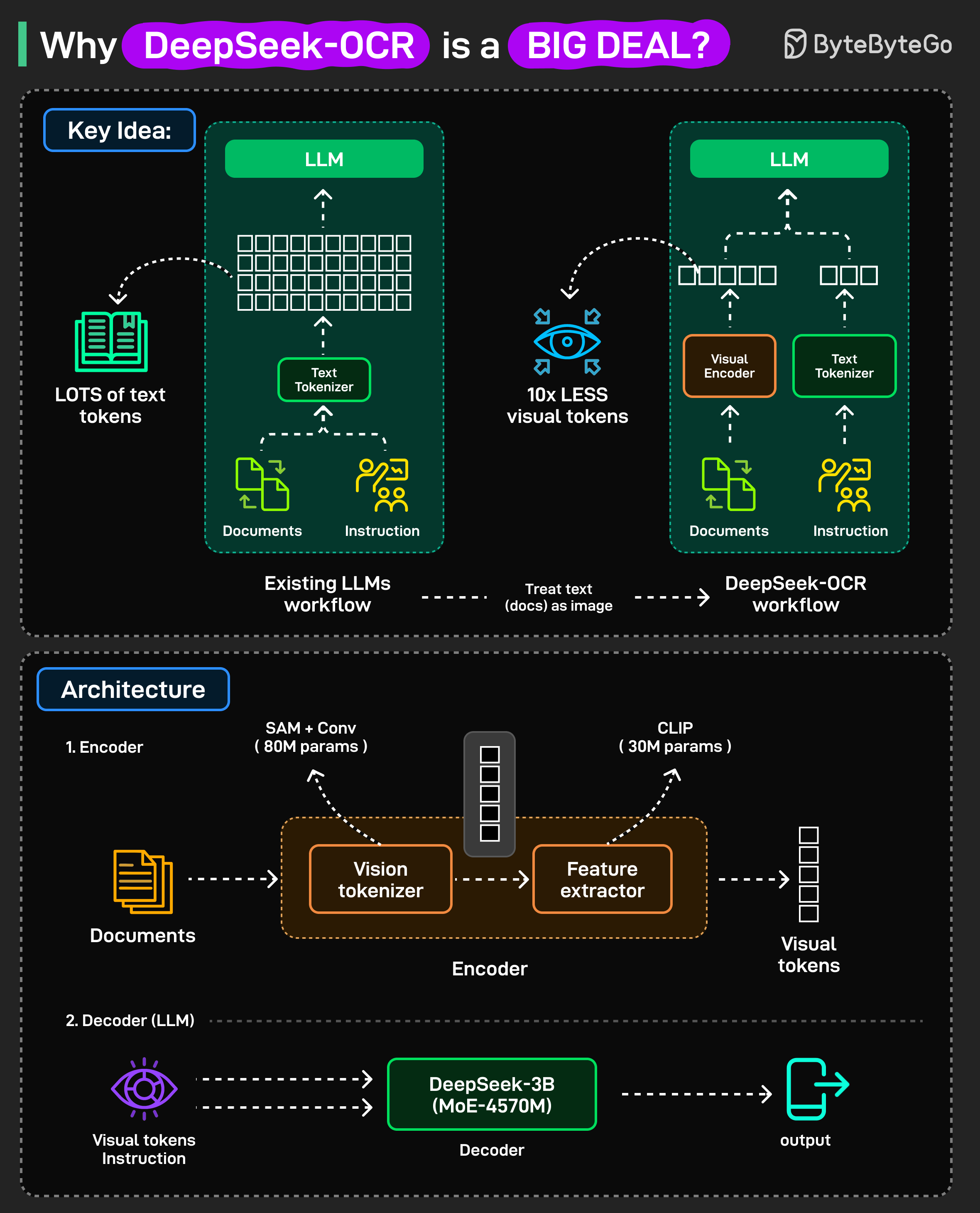
긴 context를 LLM에 직접 보내는 대신, 이를 이미지로 변환하고, 그 이미지를 visual token으로 압축한 다음, 해당 token들을 LLM에 전달합니다.
token 수가 줄어들면 attention으로 인한 계산 비용이 낮아지고 effective context window가 커집니다. 이로 인해 챗봇과 문서 모델이 더 유능하고 효율적이 됩니다.
DeepSeek-OCR은 어떻게 구축되었을까요? 시스템은 두 가지 주요 부분으로 구성됩니다:
- Encoder: 텍스트 이미지를 처리하고, visual feature를 추출하며, 이를 소수의 vision token으로 압축합니다.
- Decoder: 해당 token들을 읽고 표준 decoder-only transformer와 유사하게 한 번에 하나의 token씩 텍스트를 생성하는 Mixture of Experts 언어 모델입니다.
언제 사용해야 할까요?
DeepSeek-OCR은 텍스트가 visual representation을 사용하여 효율적으로 압축될 수 있음을 보여줍니다.
표준 context 제한을 초과하는 매우 긴 문서를 처리하는 데 특히 유용합니다. context 압축, 표준 OCR 작업, 또는 테이블과 복잡한 레이아웃을 텍스트로 변환하는 deep parsing에 사용할 수 있습니다.
여러분에게 질문: LLM의 long-context 문제를 처리하기 위해 visual token을 사용하는 것에 대해 어떻게 생각하시나요? 이것이 대형 모델의 다음 표준이 될 수 있을까요?
Related Articles
Thank you for reading.