EP189: 좋은 API를 설계하는 방법
이번 주 시스템 설계 리프레셔:
-
System Design: Why is Kafka Popular? (유튜브 영상)
-
좋은 API를 설계하는 방법
-
AWS, Azure, Google Cloud 빅데이터 파이프라인 치트시트
-
AWS 학습 방법
-
AI Agent 기술 스택
-
AWS에서 기본 RAG 애플리케이션 구축하기
-
가상화의 유형
좋은 API를 설계하는 방법
잘 설계된 API는 눈에 보이지 않는 것처럼 느껴집니다. 그냥 작동하기 때문입니다. 그 단순함 뒤에는 API를 예측 가능하고, 안전하며, 확장 가능하게 만드는 일관된 설계 원칙들이 자리하고 있습니다.
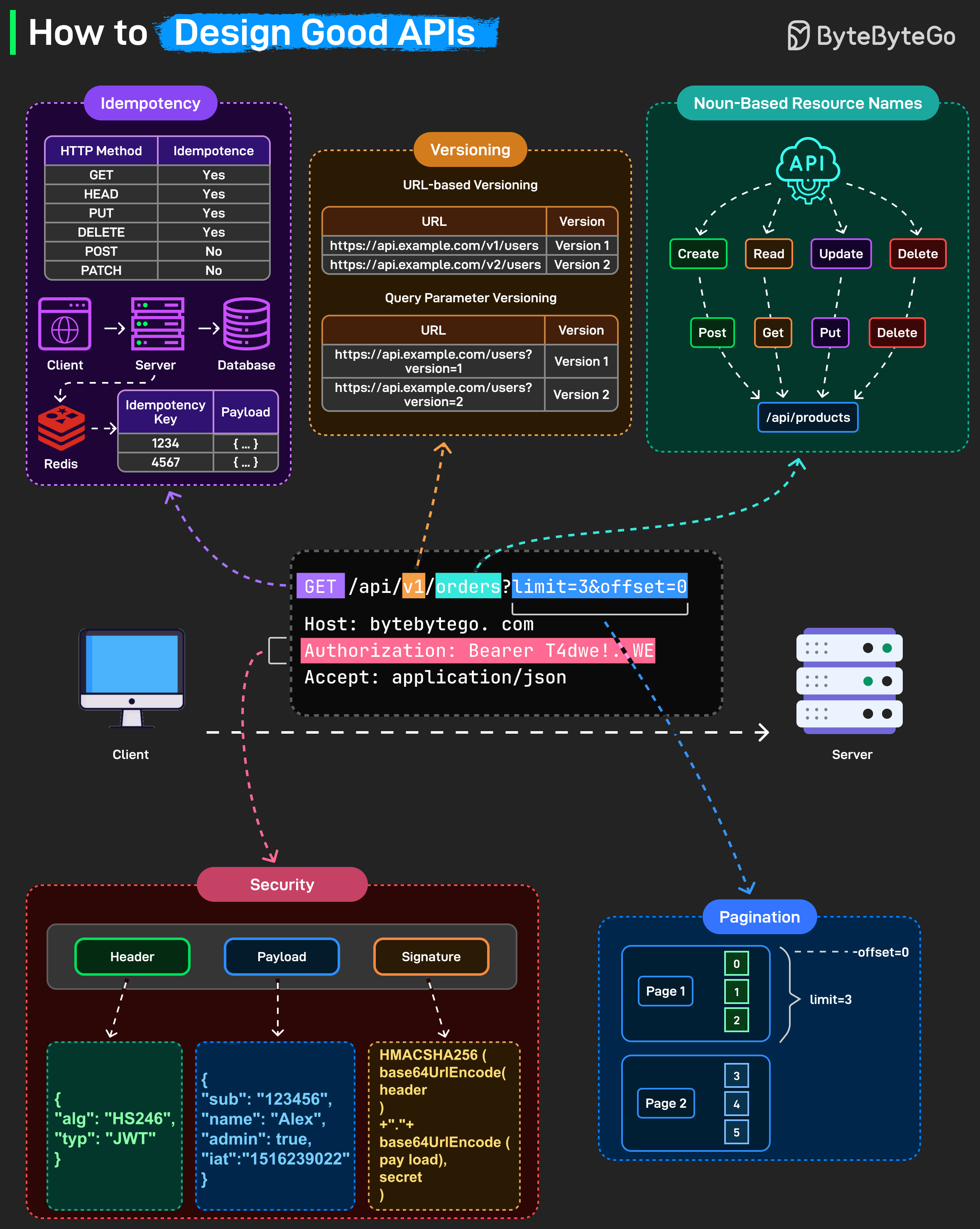
좋은 API와 형편없는 API를 구분하는 요소들은 다음과 같습니다:
1. Idempotency (멱등성)
GET, HEAD, PUT, DELETE는 멱등성을 가져야 합니다. 동일한 요청을 두 번 보내도 동일한 결과를 얻어야 합니다. 의도하지 않은 부작용이 없어야 합니다.
POST와 PATCH는 멱등성이 없습니다. 각 호출이 새로운 리소스를 생성하거나 상태를 다르게 수정합니다.
구현 방법: Redis나 데이터베이스에 저장된 멱등성 키를 사용합니다. 클라이언트가 재시도할 때 동일한 키를 보내면, 서버가 이를 인식하고 다시 처리하는 대신 원래 응답을 반환합니다.
2. Versioning (버전 관리)
API 버전 관리는 하위 호환성을 유지하면서 API를 발전시킬 수 있게 해줍니다.
3. 명사 기반 리소스 이름
리소스는 동사가 아닌 명사로 표현해야 합니다.
-
올바른 예:
/api/products -
잘못된 예:
/api/getProducts
4. Security (보안)
모든 엔드포인트를 적절한 인증으로 보호하세요. Bearer 토큰(예: JWT)은 헤더, 페이로드, 서명을 포함하여 요청을 검증합니다. 항상 HTTPS를 사용하고 모든 호출에서 토큰을 검증하세요.
5. Pagination (페이지네이션)
대용량 데이터셋을 반환할 때는 ?limit=10&offset=20과 같은 페이지네이션 파라미터를 사용하여 응답을 효율적이고 일관되게 유지하세요.
여러분에게 질문: 가장 흔히 보셨던 API 설계 실수는 무엇이며, 어떻게 고치시겠습니까?
AWS, Azure, Google Cloud 빅데이터 파이프라인 치트시트
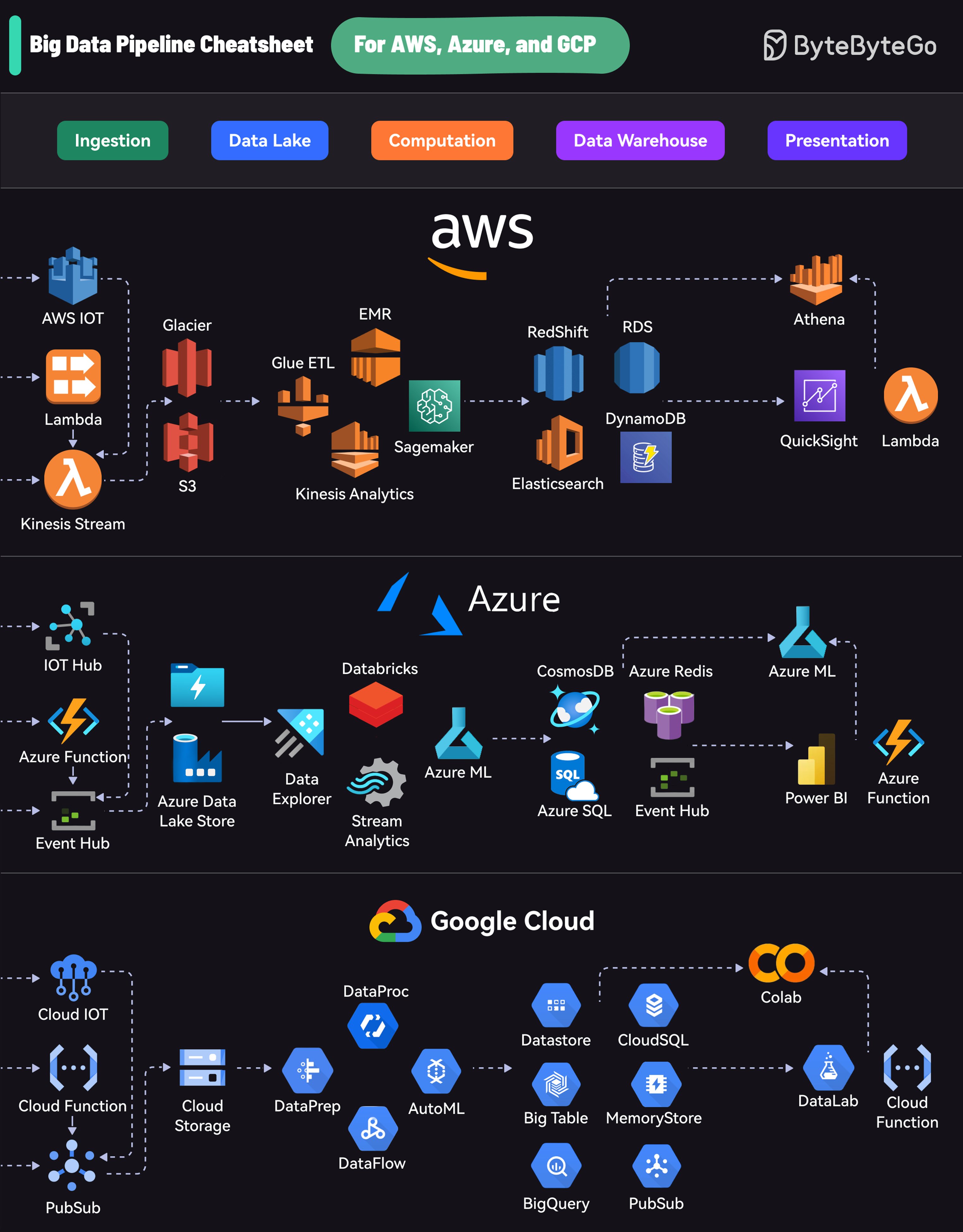
각 플랫폼은 전체 라이프사이클을 커버하는 종합적인 서비스 스위트를 제공합니다:
-
Ingestion (수집): 다양한 소스로부터 데이터 수집
-
Data Lake (데이터 레이크): 원시 데이터 저장
-
Computation (연산): 데이터 처리 및 분석
-
Data Warehouse (데이터 웨어하우스): 구조화된 데이터 저장
-
Presentation (프레젠테이션): 인사이트 시각화 및 리포팅
AWS
Kinesis로 데이터 스트리밍, S3로 스토리지, EMR로 처리, RedShift로 웨어하우징, QuickSight로 시각화를 사용합니다.
Azure
Event Hubs로 수집, Data Lake Store로 스토리지, Databricks로 처리, Cosmos DB로 웨어하우징, Power BI로 프레젠테이션을 포함합니다.
GCP
PubSub으로 데이터 스트리밍, Cloud Storage로 데이터 레이크, DataProc과 DataFlow로 처리, BigQuery로 웨어하우징, Data Studio로 시각화를 제공합니다.
여러분에게 질문: 파이프라인에 어떤 것을 더 추가하시겠습니까?
AWS 학습 방법
AWS는 가장 인기 있는 클라우드 플랫폼 중 하나입니다. AWS가 다운되면 인터넷의 상당 부분이 다운됩니다.
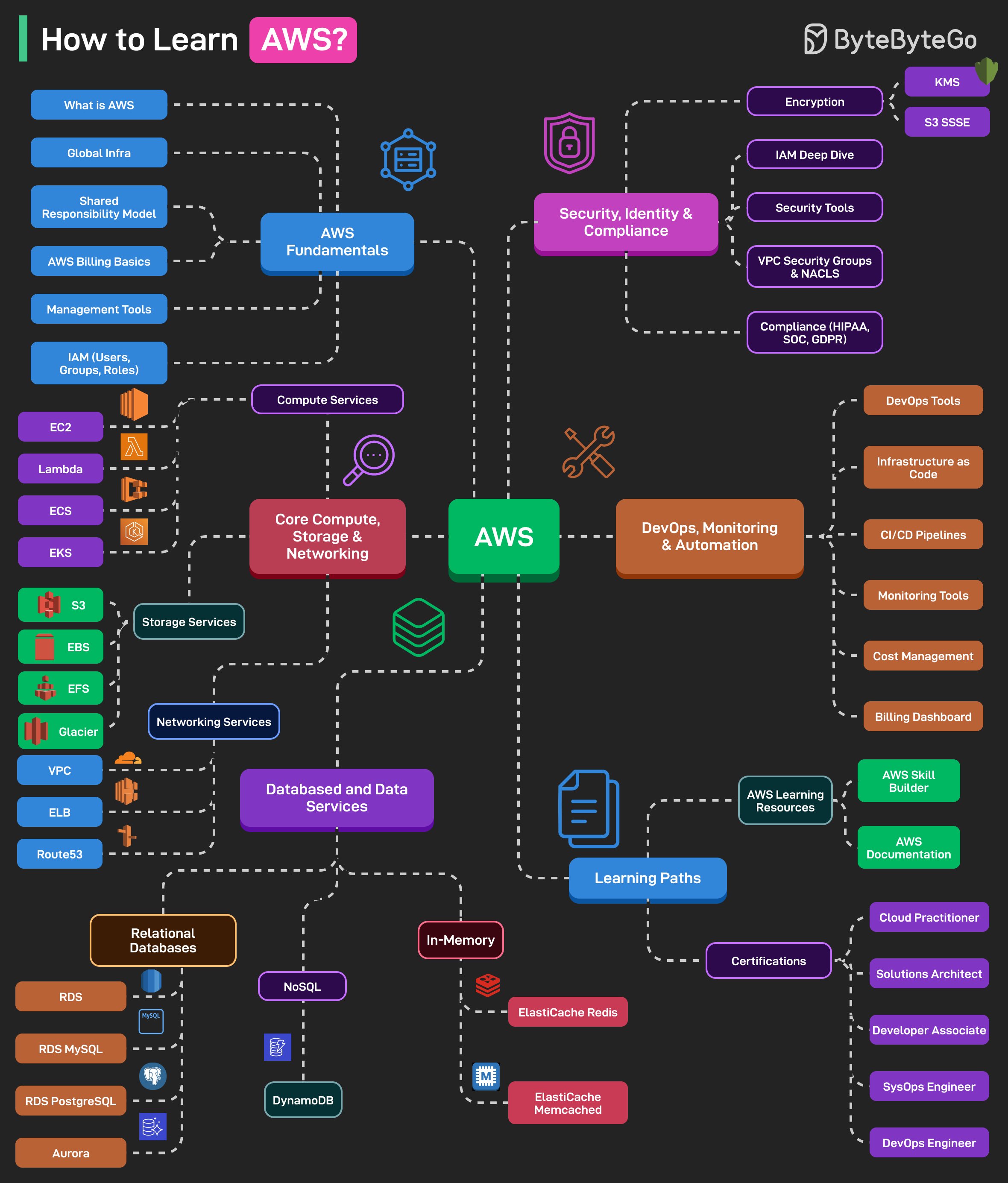
AWS를 마스터하는 데 도움이 되는 학습 로드맵은 다음과 같습니다:
1. AWS Fundamentals (기초)
"AWS란 무엇인가?", Global Infrastructure, AWS Billing, Management, IAM 기초 등의 주제를 포함합니다.
2. Core Compute, Storage & Networking
-
Compute 서비스: EC2, Lambda, ECS, EKS
-
Storage 서비스: S3, EBS, EFS, Glacier
-
Networking 서비스: VPC, ELB, Route 53
3. Databases and Data Services
Relational Databases(RDS MySQL, PostgreSQL), NoSQL, ElastiCache(Redis, Memcached)와 같은 In-Memory 데이터베이스를 포함합니다.
4. Security, Identity & Compliance
IAM 심화, Encryption(KMS, S3 SSE), Security Tools, VPC Security Groups, HIPAA/SOC/GDPR 관련 Compliance 도구를 다룹니다.
5. DevOps, Monitoring & Automation
-
DevOps 도구: CodeCommit, CodeBuild, CodePipeline
-
Infrastructure as Code
-
CI/CD Pipelines
-
Monitoring 도구: CloudWatch, CloudTrail
-
Cost Management 및 Billing Dashboard
6. Learning Paths and Certifications
AWS Skill Builder, 문서 등의 학습 리소스와 Cloud Practitioner, Solutions Architect Associate, Developer Associate, SysOps, DevOps Engineer 등의 자격증 경로를 포함합니다.
여러분에게 질문: AWS 학습 목록에 어떤 것을 더 추가하시겠습니까?
AI Agent 기술 스택

Foundation Models
AI Agent의 "두뇌" 역할을 하는 대규모 사전 훈련된 언어 모델입니다. 추론, 텍스트 생성, 코딩, 질문 응답과 같은 기능을 가능하게 합니다.
Data Storage
AI Agent가 컨텍스트, 임베딩, 또는 문서를 저장하고 검색하는 데 사용하는 벡터 데이터베이스와 메모리 스토리지 시스템을 처리하는 레이어입니다.
Agent Development Frameworks
개발자가 다단계 AI Agent와 워크플로우를 구축, 조율, 관리할 수 있도록 돕는 프레임워크입니다.
Observability
실시간으로 AI Agent 행동과 성능을 모니터링, 디버깅, 로깅할 수 있게 해주는 카테고리입니다.
Tool Execution
AI Agent가 복잡한 작업을 완료하기 위해 실제 도구(API, 브라우저, 외부 시스템 등)와 인터페이스할 수 있게 해주는 플랫폼입니다.
Memory Management
Agent의 장기 및 단기 메모리를 관리하여 유용한 컨텍스트를 유지하고 과거 상호작용에서 학습할 수 있도록 돕는 시스템입니다.
여러분에게 질문: 목록에 어떤 것을 더 추가하시겠습니까?
AWS에서 기본 RAG 애플리케이션 구축하기
RAG는 검색 단계와 텍스트 생성을 결합한 AI 패턴입니다. 벡터 데이터베이스와 같은 지식 소스에서 관련 정보를 검색한 다음 LLM을 사용하여 정확하고 컨텍스트를 인식하는 응답을 생성합니다.
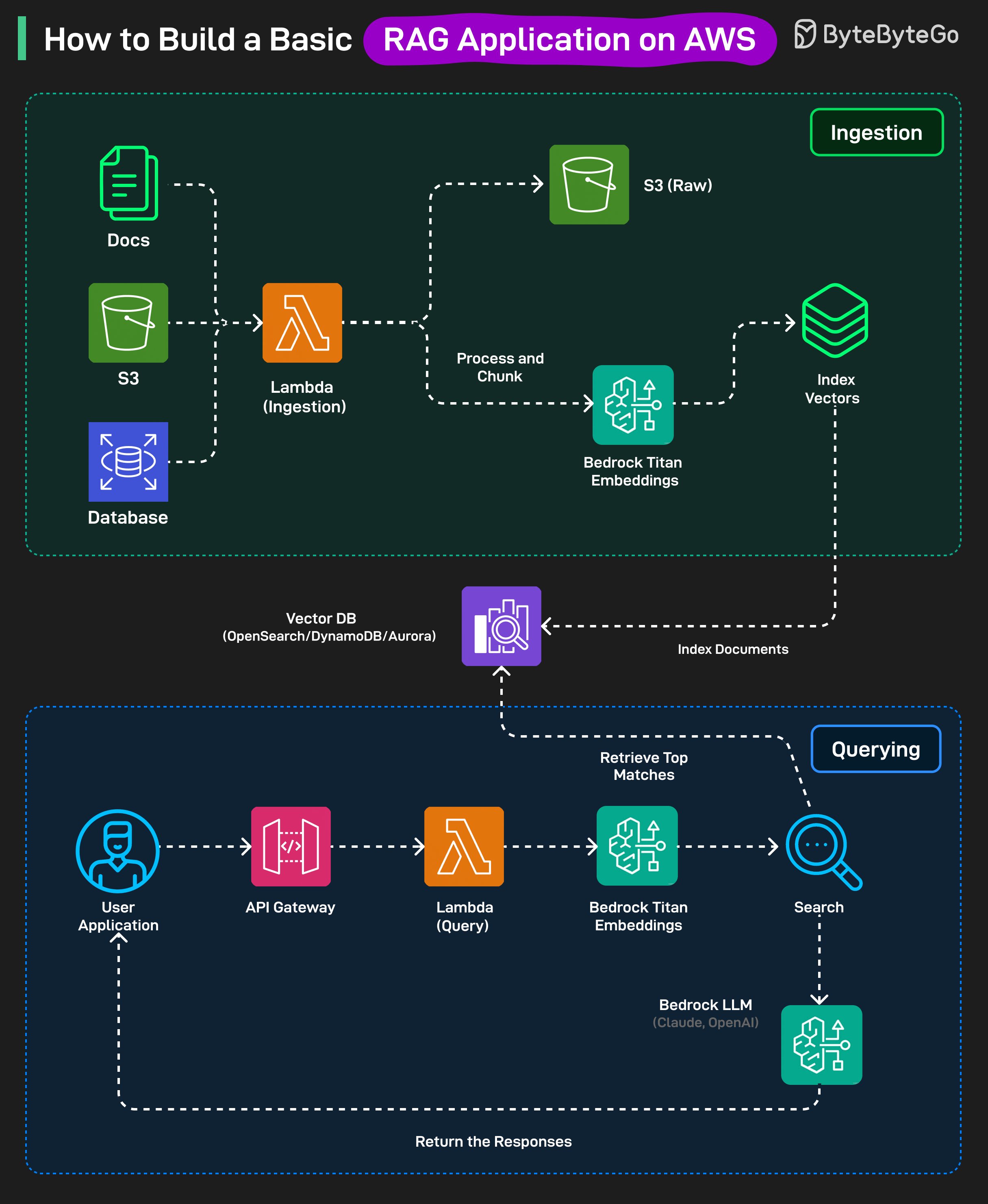
Ingestion Stage (수집 단계)
-
모든 원시 문서(PDF, 텍스트 등)는 먼저 Amazon S3에 저장됩니다.
-
파일이 추가되면 AWS Lambda가 수집 함수를 실행합니다. 이 함수는 문서를 정리하고 더 작은 청크로 분할합니다.
-
각 청크는 Amazon Bedrock의 Titan 임베딩 모델로 전송되어 벡터 표현으로 변환됩니다.
-
이러한 임베딩은 메타데이터와 함께 OpenSearch Serverless, DynamoDB와 같은 벡터 데이터베이스에 저장됩니다.
Querying Stage (쿼리 단계)
-
사용자가 앱 프론트엔드를 통해 질문을 보내면, API Gateway를 거쳐 Lambda 쿼리 함수로 전달됩니다.
-
질문은 Amazon Bedrock Titan Embeddings를 사용하여 임베딩으로 변환됩니다.
-
이 임베딩은 벡터 데이터베이스에 저장된 문서 임베딩과 비교되어 가장 관련성 높은 청크를 찾습니다.
-
관련 청크와 사용자의 질문이 LLM(Bedrock의 Claude나 OpenAI 등)으로 전송되어 답변을 생성합니다.
-
생성된 응답은 동일한 API를 통해 사용자에게 다시 전송됩니다.
여러분에게 질문: AWS에서 RAG 앱을 구축하는 데 어떤 다른 AWS 서비스를 사용하시겠습니까?
가상화의 유형
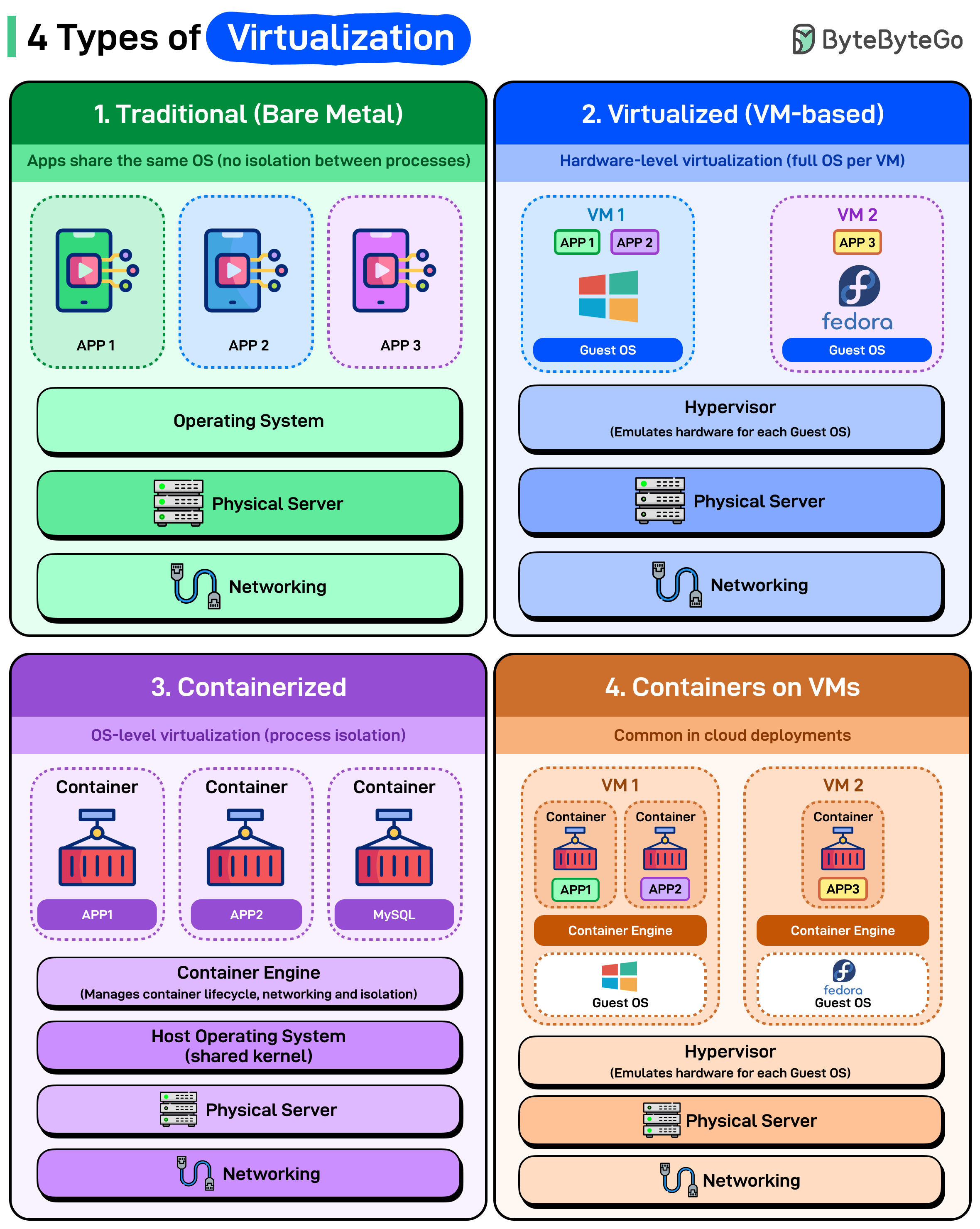
가상화는 서버를 효율적으로 만든 것뿐만 아니라, 우리가 모든 것을 구축하고, 확장하고, 배포하는 방식을 바꿨습니다. 현대 시스템에서 볼 수 있는 네 가지 주요 가상화 유형에 대한 간략한 분석입니다:
1. Traditional (Bare Metal)
애플리케이션이 운영 체제에서 직접 실행됩니다. 가상화 레이어도 없고 프로세스 간 격리도 없습니다. 모든 애플리케이션이 동일한 OS 커널, 라이브러리, 리소스를 공유합니다.
2. Virtualized (VM 기반)
각 VM이 자체적으로 완전한 운영 체제를 실행합니다. 하이퍼바이저가 물리적 하드웨어 위에 위치하여 각 게스트 OS에 대해 전체 머신을 에뮬레이션합니다. 각 VM은 동일한 물리적 서버를 공유하면서도 전용 하드웨어가 있다고 생각합니다.
3. Containerized
컨테이너는 호스트 운영 체제의 커널을 공유하지만 격리된 런타임 환경을 갖습니다. 각 컨테이너는 자체 파일시스템을 가지지만 모두 동일한 기본 OS를 사용합니다. 컨테이너 엔진(Docker, containerd, Podman)이 각 애플리케이션에 대해 별도의 운영 체제 없이 라이프사이클, 네트워킹, 격리를 관리합니다.
가볍고 빠릅니다. OS를 부팅하지 않기 때문에 컨테이너는 밀리초 단위로 시작됩니다. 리소스 사용량이 VM보다 극적으로 낮습니다.
4. Containers on VMs
이것이 실제로 프로덕션 클라우드 환경에서 실행되는 방식입니다. VM 내부의 컨테이너로, 둘 다의 이점을 얻습니다. 각 VM은 내부에 컨테이너 엔진이 있는 자체 게스트 OS를 실행합니다. 하이퍼바이저가 VM 간에 하드웨어 수준의 격리를 제공합니다. 컨테이너 엔진은 VM 내에서 경량 애플리케이션 격리를 제공합니다.
이것이 AWS, Azure, GCP의 Kubernetes 클러스터 뒤에 있는 아키텍처입니다. 여러분의 Pod는 컨테이너이지만, 직접 보거나 관리하지 않는 VM 내에서 실행되고 있습니다.
여러분에게 질문: 경험상 성능과 유연성 사이에서 가장 좋은 균형을 이루는 설정은 무엇입니까?
Related Articles
Thank you for reading.